
定義済みモデルの組み込み
モデルプロバイダーの作成が完了していることを確認してください。事前定義済みモデルを組み込むには、以下の手順に従います。
モデルタイプに応じたモジュール構造の作成
モデルのタイプ(
llmやtext_embeddingなど)に応じて、プロバイダーモジュール内に対応するサブモジュールを作成します。各モデルタイプが独立した論理構造を持つようにすることで、保守性と拡張性を高めます。モデル呼び出しコードの記述
対応するモデルタイプのモジュール内に、モデルタイプと同名のPythonファイル(例:llm.py)を作成します。ファイル内に、具体的なモデルロジックを実装するクラスを定義します。このクラスは、システムのモデルインターフェース仕様に準拠している必要があります。
事前定義済みモデル設定の追加
プロバイダーが事前定義済みモデルを提供している場合、各モデルに対してモデル名と同名の
YAMLファイル(例:claude-3.5.yaml)を作成します。AIModelEntityの仕様に従ってファイルの内容を記述し、モデルのパラメータと機能を定義します。プラグインのテスト
新たに追加されたプロバイダー機能に対して、ユニットテストと統合テストを作成し、すべての機能モジュールが期待どおりに動作することを確認します。
以下は、組み込みの詳細な手順です。
1. モデルタイプに応じたモジュール構造の作成
モデルプロバイダーは、OpenAIが提供するllmやtext_embeddingのように、様々なモデルタイプを提供することがあります。プロバイダーモジュール内に、これらのモデルタイプに対応するサブモジュールを作成し、各モデルタイプが独立した論理構造を持つようにすることで、保守性と拡張性を高めます。
現在サポートされているモデルタイプは以下のとおりです。
llm: テキスト生成モデルtext_embedding: テキスト埋め込みモデルrerank: Rerankモデルspeech2text: 音声テキスト変換tts: テキスト音声変換moderation: 審査
Anthropicを例にとると、そのシリーズモデルにはLLMタイプのモデルのみが含まれているため、/modelsパスに/llmフォルダを新規作成し、異なるモデルのYAMLファイルを追加するだけで済みます。詳細なコード構造については、GitHubコードリポジトリを参照してください。
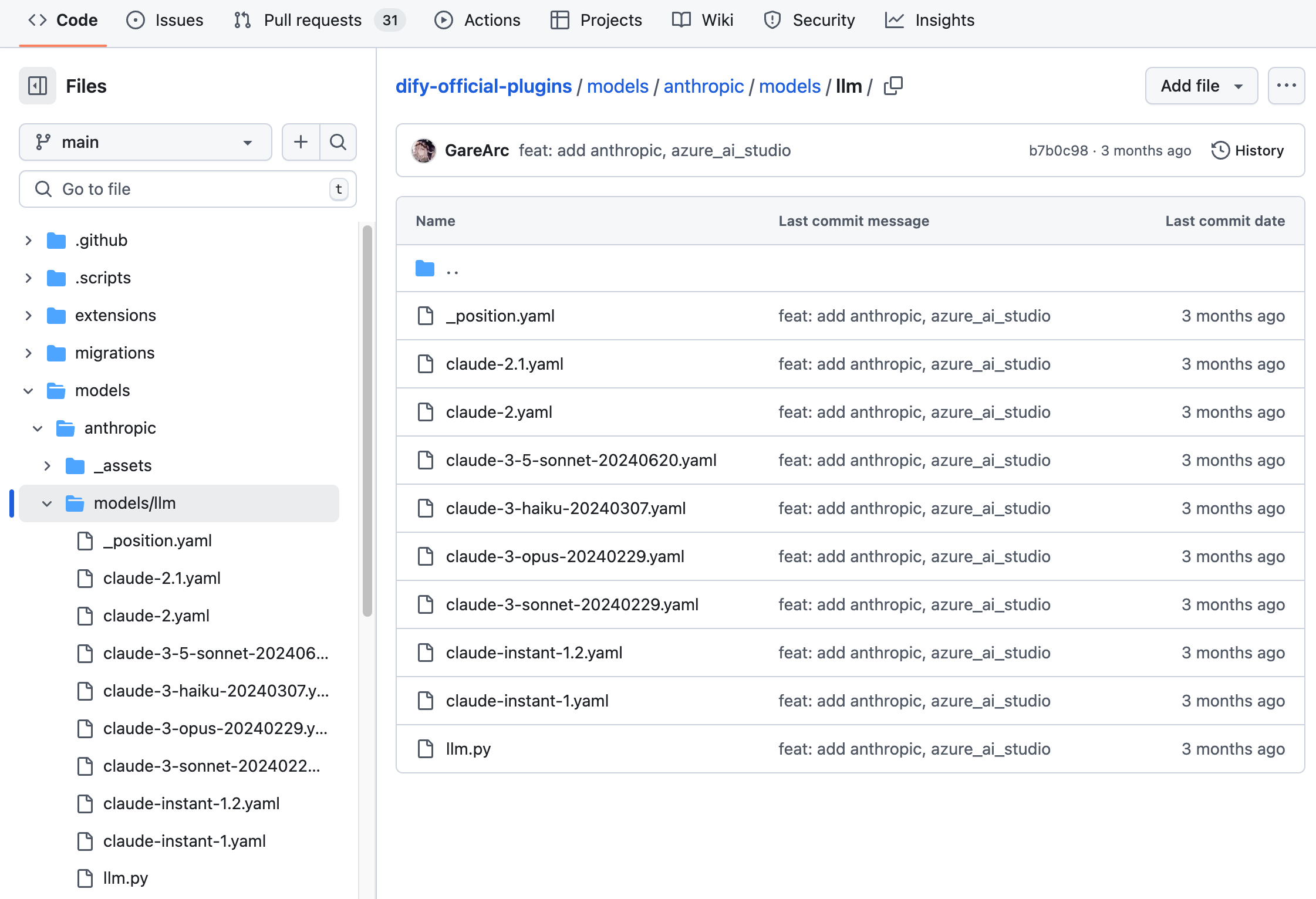
OpenAIのファミリーモデルのように、モデルプロバイダーがllm、text_embedding、moderation、speech2text、ttsなど、さまざまなタイプのモデルを提供している場合は、/modelsパスに各タイプに対応するフォルダを作成する必要があります。構造は以下のようになります。
すべてのモデル設定を準備してから、モデルコードの実装を開始することをお勧めします。完全なYAMLの記述規則については、モデル設計規則を参照してください。詳細なコードについては、Githubコードリポジトリの例を参照してください。
2. モデル呼び出しコードの記述
次に、/modelsパスにllm.pyというコードファイルを作成する必要があります。Anthropicを例にとると、llm.pyにAnthropic LLMクラスを作成し、AnthropicLargeLanguageModelという名前を付け、__base.large_language_model.LargeLanguageModel基本クラスを継承します。
以下に、一部の機能のサンプルコードを示します。
LLMの呼び出し
LLMをリクエストする主要なメソッドです。ストリーミングと同期の両方のレスポンスをサポートします。
実装時には、同期リターンとストリームリターンを個別に処理するために、2つの関数を使用する必要があることに注意してください。これは、Pythonでyieldキーワードを含む関数はジェネレーター関数として認識され、その戻り値の型がGeneratorに固定されるためです。ロジックを明確にし、様々なリターンの要求に対応するために、同期リターンとストリームリターンは個別に実装する必要があります。
以下はサンプルコードです(サンプルではパラメータが簡略化されています。実際の実装では、完全なパラメータリストに従って記述してください)。
入力トークン数の事前計算
モデルがトークン数の事前計算インターフェースを提供していない場合は、この機能が適用されないか、実装されていないことを示すために、直接0を返すことができます。例:
呼び出し例外エラーマッピングテーブル
モデル呼び出しが例外の場合、Difyがさまざまなエラーに対して適切な処理を実行できるように、Runtimeによって指定されたInvokeErrorタイプにマッピングする必要があります。
Runtime Errors:
InvokeConnectionError: 呼び出し接続エラーInvokeServerUnavailableError: 呼び出しサービスが利用不可InvokeRateLimitError: 呼び出しが制限に達しましたInvokeAuthorizationError: 呼び出し認証に失敗しましたInvokeBadRequestError: 呼び出しパラメータにエラーがあります
完全なコードの詳細については、Githubコードリポジトリを参照してください。
3. 事前定義済みモデル設定の追加
プロバイダーが事前定義済みモデルを提供している場合、各モデルに対してモデル名と同名のYAMLファイル(例:claude-3.5.yaml)を作成します。AIModelEntityの仕様に従ってファイルの内容を記述し、モデルのパラメータと機能を定義します。
claude-3-5-sonnet-20240620モデルのサンプルコード:
4. プラグインのデバッグ
次に、プラグインが正常に動作するかどうかをテストする必要があります。Difyはリモートデバッグ方法を提供しており、「プラグイン管理」ページでデバッグキーとリモートサーバーアドレスを取得できます。
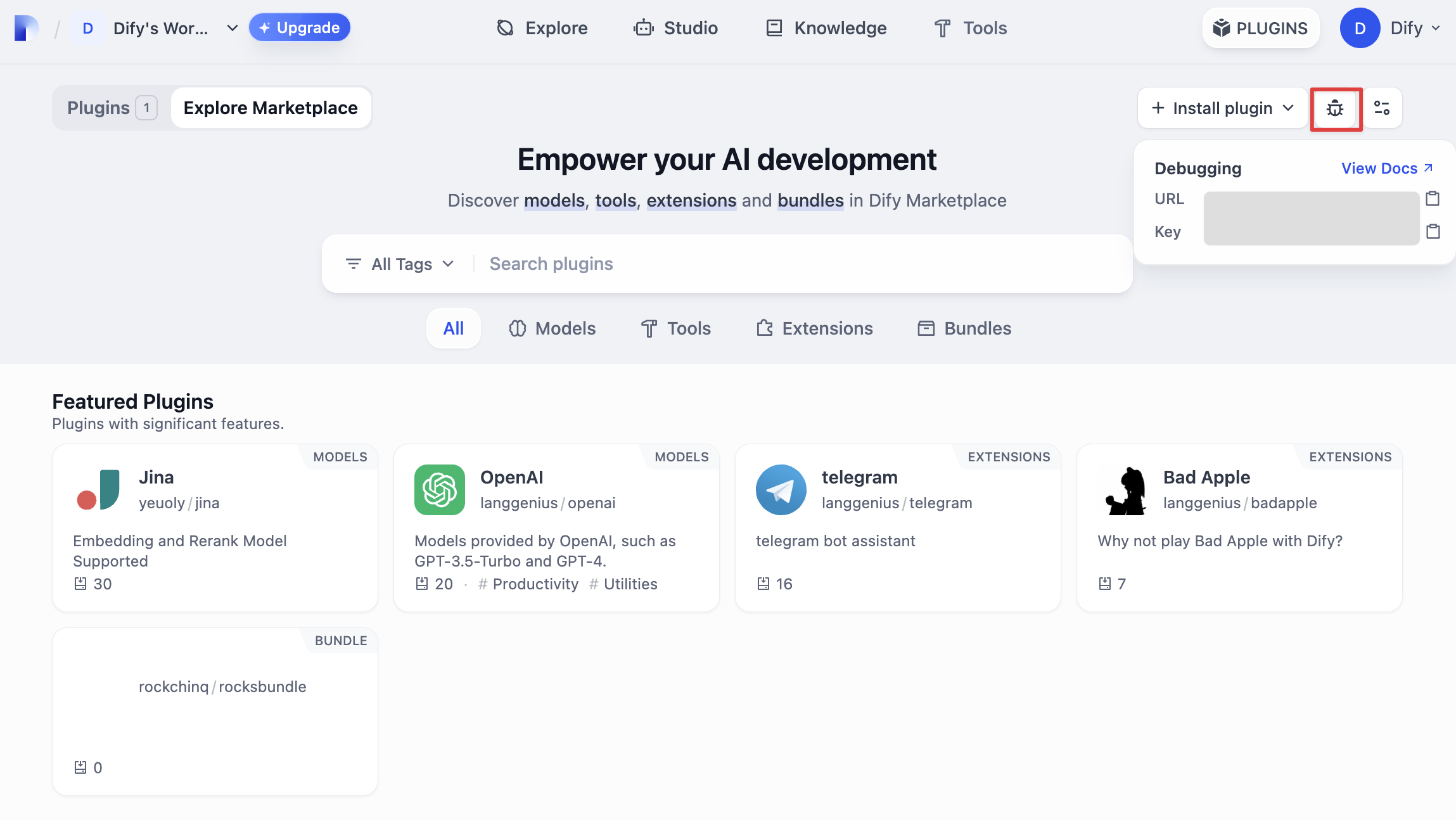
プラグインプロジェクトに戻り、.env.exampleファイルをコピーして.envにリネームし、取得したリモートサーバーアドレスとデバッグKeyなどの情報を入力します。
.env ファイル
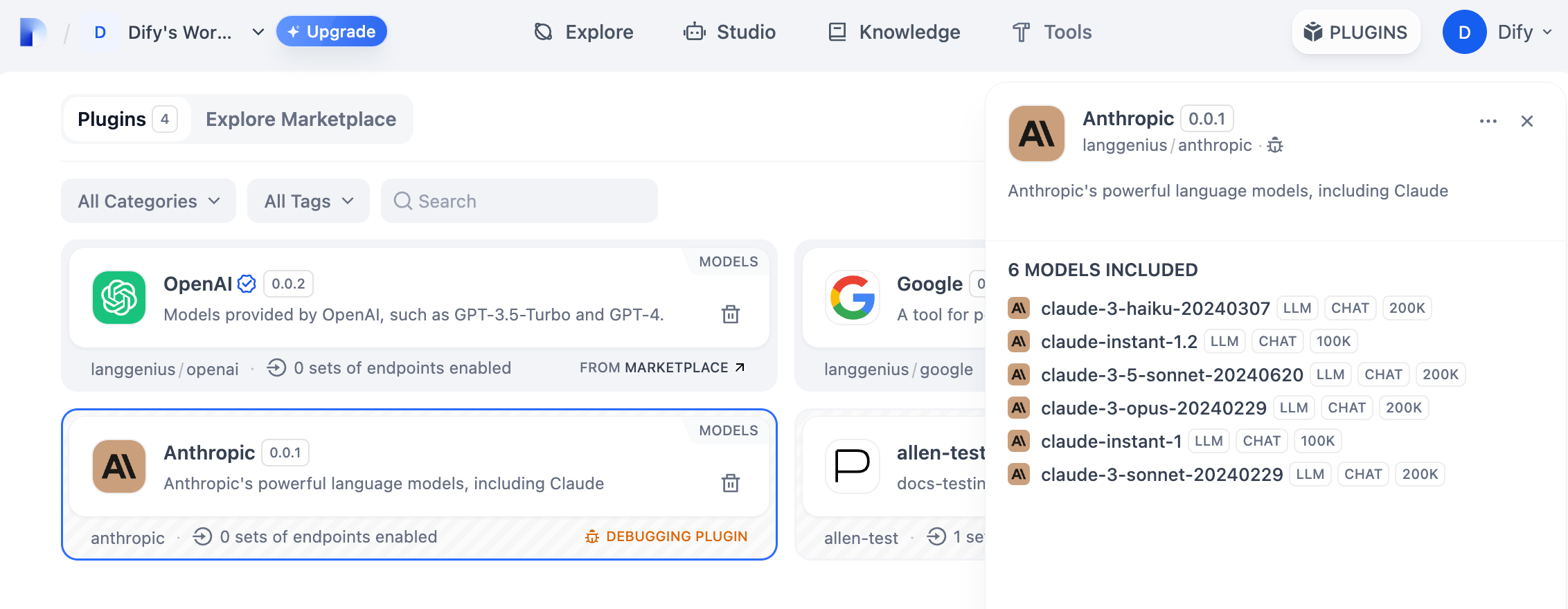
python -m mainコマンドを実行してプラグインを起動します。プラグインページで、そのプラグインがWorkspaceにインストールされていることを確認できます。他のチームメンバーもこのプラグインにアクセスできます。
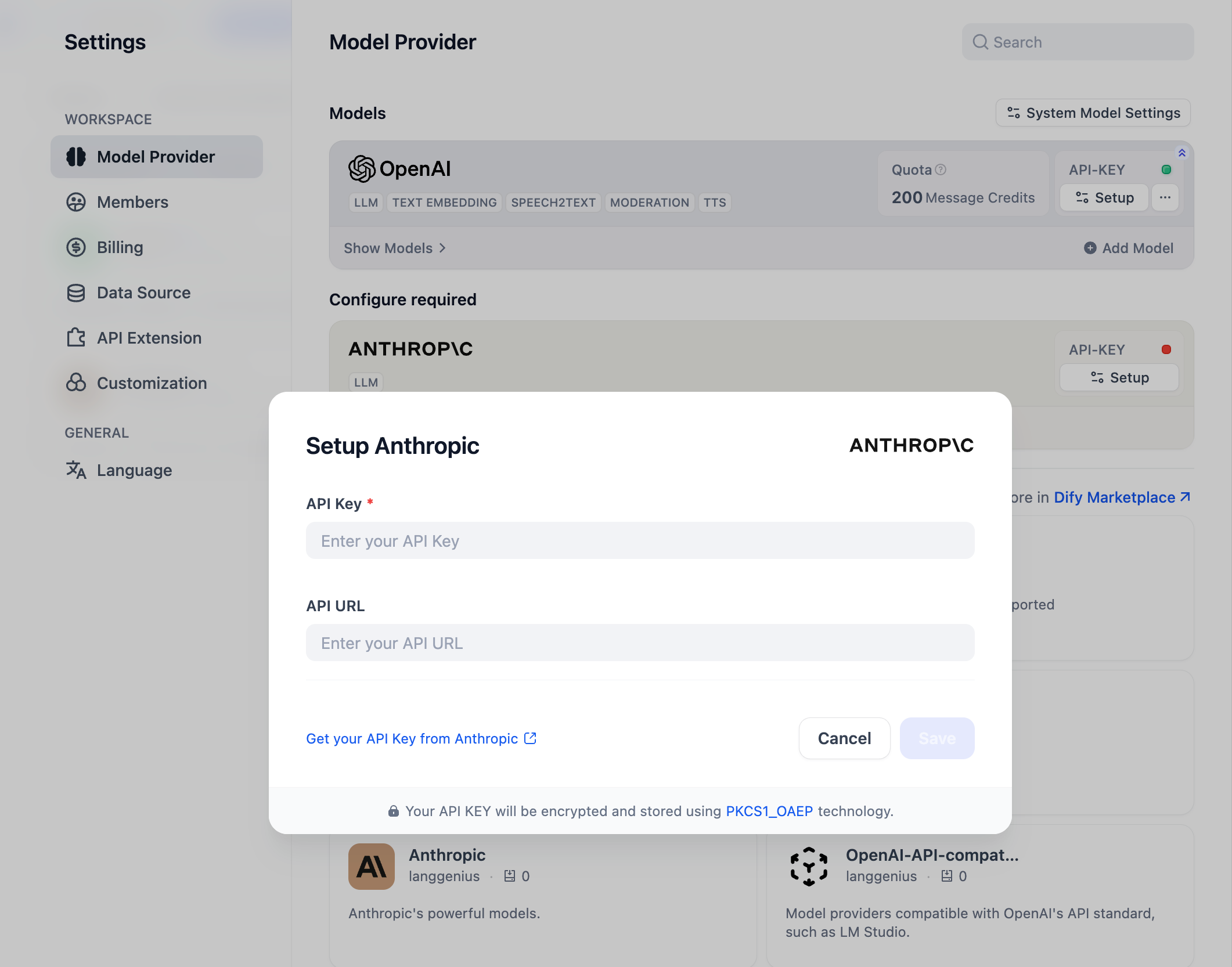
「設定」→「モデルプロバイダー」でAPI Keyを入力して、モデルプロバイダーを初期化できます。
プラグインの公開
作成したプラグインをDify Pluginsコードリポジトリにアップロードして公開できます。アップロードする前に、プラグインがプラグイン公開仕様に準拠していることを確認してください。審査に合格すると、コードがメインブランチにマージされ、Dify Marketplaceに自動的に公開されます。
さらに詳しく
クイックスタート:
プラグインインターフェースドキュメント:
Last updated