
繰り返し処理(ループ)
概要
繰り返し処理(ループ)ノードは、前回の結果に依存する反復タスクを実行し、終了条件を満たすか最大繰り返し回数に達するまで継続します。
繰り返し処理ノードと反復処理ノードの違い
繰り返し処理(ループ)
各回の処理が前回の結果に依存する。
前回の計算結果を必要とする処理に適している。
反復処理(イテレーション)
各回の処理は独立しており、前回の結果に依存しない。
データの一括処理など、各処理を独立して実行できるタスクに適している。
繰り返し処理(ループ)ノードの設定方法
ループ終了条件
ループを終了するタイミングを決定する式
x < 50、error_rate < 0.01
最大繰り返し回数
無限ループを防ぐための繰り返し回数の上限
10、100、1000
ループ変数
反復ごとにデータが受け渡され、ループ終了後も後続ノードで利用可能です。
変数 x < 50 はループごとに1ずつ増加し、ループ内では x < 50 の値に基づいて計算を実行できます。ループ終了後、x < 50 の最終値は後続の処理で利用可能です。
ループ終了ノード
ループ内でこのノードに到達すると、ループが終了します。
終了条件に関係なく、最大10回ループします。
ループ終了ノードとループ終了条件はどちらもループの終了トリガーとして機能し、いずれかの条件が満たされるとループは早期に終了します。
終了条件が設定されていない場合、ループは最大ループ回数に達するまで継続して実行されます(while (true)と同等です)。
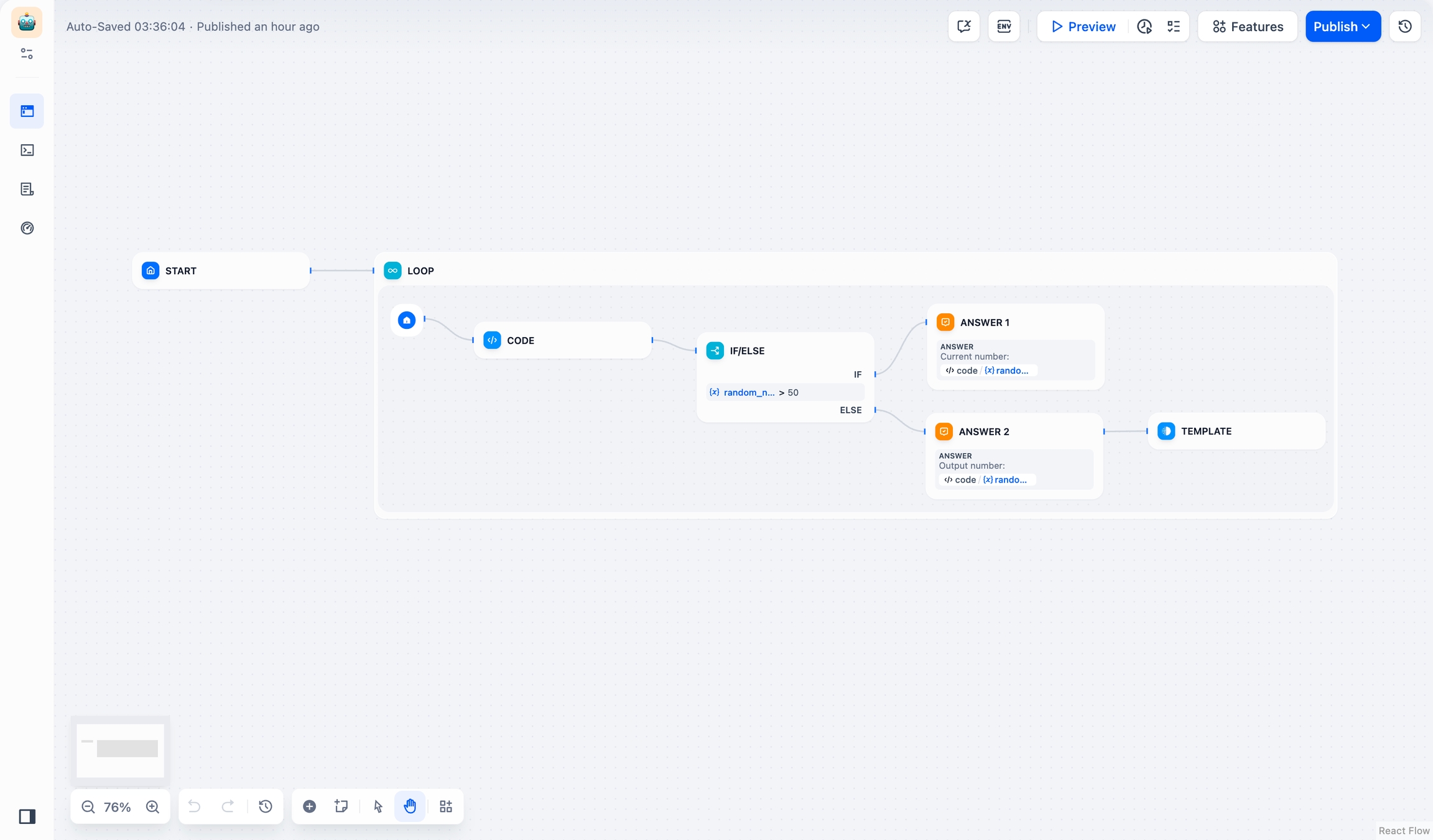
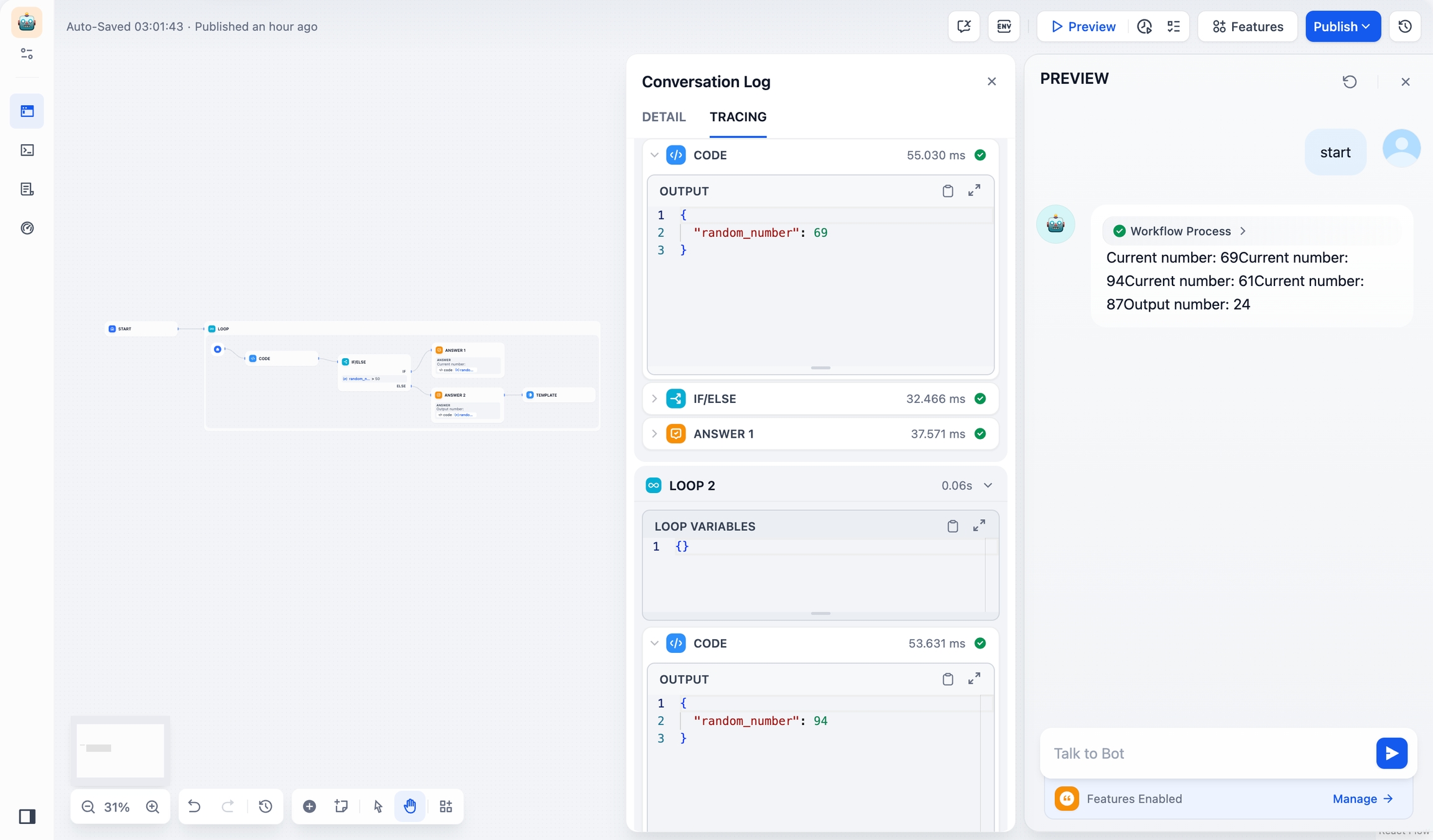
サンプル1:ループノードの使い方
要件:1〜100の乱数を生成し、乱数が50未満になったら停止します。
実装手順:
ループノードで、ループ終了条件をテンプレートノードの出力が
doneになるように設定します。コード実行ノードを使用して、
1〜100の乱数を生成します。条件分岐ノードを使用して、乱数が
50より大きいかどうかを判断します。
50以上の場合、
現在の数字を出力し、ループを継続して新しい乱数を生成します。50未満の場合、
最終出力数字を出力し、テンプレートノードを経由してdoneを出力し、ループを終了します。
乱数が
50未満になると、ループは自動的に停止します。
サンプル2:ループ変数とループ終了ノードの使い方
要件:ループワークフローを使用して詩を生成し、段階的に書き直し、各出力は前のループの結果に基づきます。ループは4回実行された後に自動的に停止します。
実装手順:
ループノードで、各イテレーションでデータを渡すために使用する ループ変数 を設定します。
num(ループ回数):初期値は0で、ループごとに+1されます。
verse(詩の内容):初期値は
I haven't started creating yetで、後続の各ループで更新されます。
条件分岐ノードを使用して、ループ回数が
3より大きいかどうかを判断します。
3 より大きい場合、ループ終了ノードに到達し、ループを終了します。
3 以下の場合、LLMノードに到達し、ループを継続します。
LLMノードを使用して、ユーザーの入力と過去の作品に基づいて詩の内容を出力するようにモデルに指示します。
プロンプト例:
ユーザーの入力
sys.queryをもとに、ヨーロッパの長詩を作成してください。前回の作成結果
verseを参考に、新しい詩句で進歩と革新を示してください。詩句がヨーロッパ文学のスタイルと伝統に合致し、韻律と意境に注意してください。
最初のループでは、verseはI haven't started creating yetです。それ以降の各ループでは、前のループの出力に基づいて詩が更新されます。モデルが生成した新しい詩は毎回verse変数を上書きし、次のループで使用されます。
変数設定ノードを使用して、各ループの後にループ内の変数を更新します。
num変数を更新し、ループごとに+1します。
verse変数をモデルが新しく生成した詩の内容に更新し、前のループの詩の内容を直接上書きします。
詩のインスピレーションを入力すると、モデルは4つのバージョンの詩を出力します。各詩は前の詩に基づいて生成されます。
Last updated