
2. チャンクモードの指定
コンテンツをナレッジベースにアップロードした後、次に行うべき作業は、コンテンツの分割とデータのクリーニングです。この段階では、コンテンツの前処理と構造化を行い、長いテキストを複数の小さなブロックに分割します。
具体的にどのように分割とクリーニングを行うのでしょうか?
分割
大規模な言語モデルが処理できる情報量には限界があるため、知識データベースのコンテンツを一度にすべて処理することはできません。このため、長い文書をより小さいコンテンツブロックに分割する必要があります。一部のモデルでは、文書全体をアップロードする機能をサポートしていますが、実験により、コンテンツをブロックごとに検索した方が効率的であることが分かっています。
言語モデルが知識データベース内の情報に基づいて正確な回答を提供できるかどうかは、コンテンツブロックの検索と選択の効果に依存します。マニュアルから必要な章を探すように、文書全体を詳細に分析することなく迅速に答えを見つけられます。分割された知識データベースでは、ユーザーの質問に基づいて、関連性が高いコンテンツブロックを選択し、重要な情報を提供することで、回答の精度を向上させます。
質問とコンテンツブロックの意味的なマッチングを行う際、適切な分割サイズが非常に重要です。これにより、モデルが問題に最も関連性が高いコンテンツを正確に特定し、無関係な情報を減らすことができます。分割が大きすぎるか小さすぎると、選択の効果に悪影響を及ぼす可能性があります。
Difyは、「汎用分割」と「階層分割」の2種類の分割モードを提供しており、それぞれ異なる文書の構造と用途に適応し、異なる検索と選択の効率と精度の要件を満たします。
クリーニング
テキストの選択効果を保証するためには、通常、データを知識データベースに入力する前にクリーニングが必要です。例えば、意味のない文字や空行が含まれている可能性があり、これらは応答の品質に影響を与えるため、クリーニングが必要です。Difyでは、自動的なクリーニング戦略が組み込まれており、詳細はETLセクションを参照してください。
ユーザーが質問した後、LLMがその質問に基づいたナレッジベースからの正確な回答を提供できるかどうかは、関連する情報ブロックを効率的に検索し取り出せるかにかかっています。AIアプリケーションが正確かつ包括的な回答を出すためには、その問題に直接関わる情報ブロックの特定が非常に重要です。
例えば、スマートカスタマーサービスの場合、LLMがツールマニュアル内の重要な章の情報ブロックをすぐに見つけ出せれば、ユーザーの問いに素早く答えられます。これにより、文書全体を何度も分析する手間が省けます。結果として、AIアプリケーションの質問応答(Q&A)機能の品質を、トークン使用量を節約しつつ向上させることができます。
ナレッジベースのセグメント分類方法の選択
私たちのナレッジベースでは、以下の2つのセグメント分類方法を提供しています。
汎用分割
注意:以前の「自動セグメント分割&クリーニング」モードは、自動で汎用分割へとアップデートされました。何も手を加える必要はありません。既定の設定でそのまま利用可能です。
親子分割(階層分割)
セグメント分類方法を選んでナレッジベースを作成した後での変更は不可能です。ナレッジベースに新たに追加される文書も、選択した同じセグメント分類方法に従います。
汎用分割モード
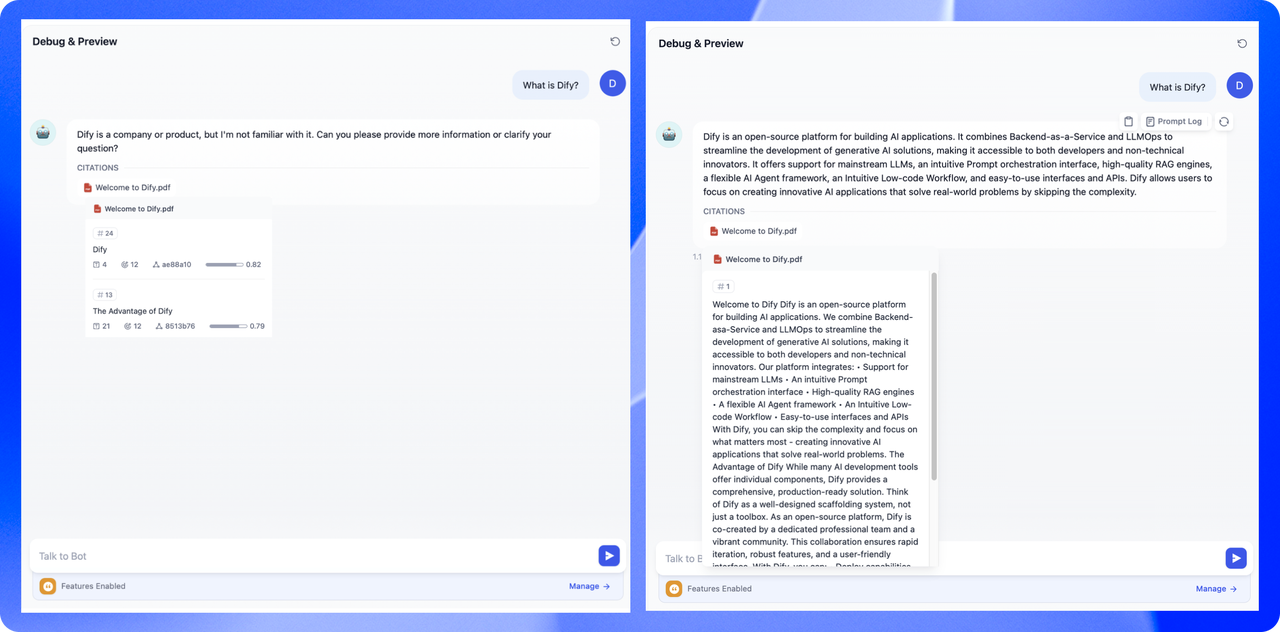
汎用分割では、システムはユーザーが設定したルールに沿ってコンテンツを独立したセグメントに分割します。ユーザーが検索クエリを入力すると、システムは自動的にそのクエリのキーワードを分析し、それらのキーワードとナレッジベース内の各コンテンツセグメントとの関連性を評価します。その後、関連性が高いものから順に並べ、最も関連性の高いコンテンツセグメントを選択し、大規模言語モデル(LLM)による処理と回答を行います。
このモードでは、異なる文書形式やシナリオの要件に応じて、以下の設定項目を参考にしながら、テキストのセグメント分割ルールを手動で調整することが必要です。
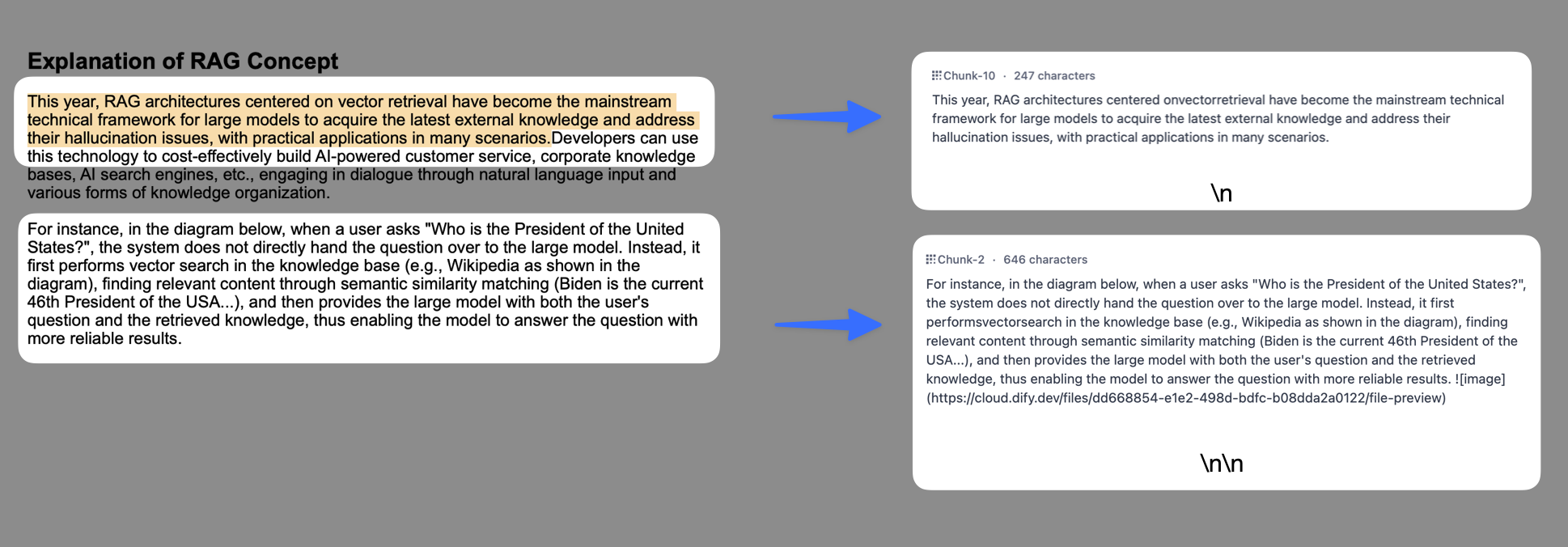
セグメント分割識別子:デフォルト値は
\nで、文書内の各段落をセグメントに分割します。正規表現のルールに従って、分割ルールをカスタマイズできます。例えば、 は各行をセグメントに分割することを意味します。下記の図は、異なる文法を用いたテキスト分割の効果を示しています:
セグメントの最大長さ:セグメント内のテキスト文字数の最大値を設定します。この長さを超えると、強制的にセグメントが分割されます。デフォルト値は 500 トークンで、セグメント長の最大値は 4000 トークンです。
セグメントの重複長さ:データをセグメントに分割する際、セグメント間で一定量の重複が生じます。この重複は情報の損失を防ぎ、分析の精度を向上させ、情報のリコール効率を高めるのに役立ちます。セグメント長の10%から25%を重複させることを推奨します。
テキスト前処理ルール:ナレッジベース内の不要な内容をフィルタリングするための設定です。
連続する空白、改行、タブを置換
すべてのURLと電子メールアドレスを削除
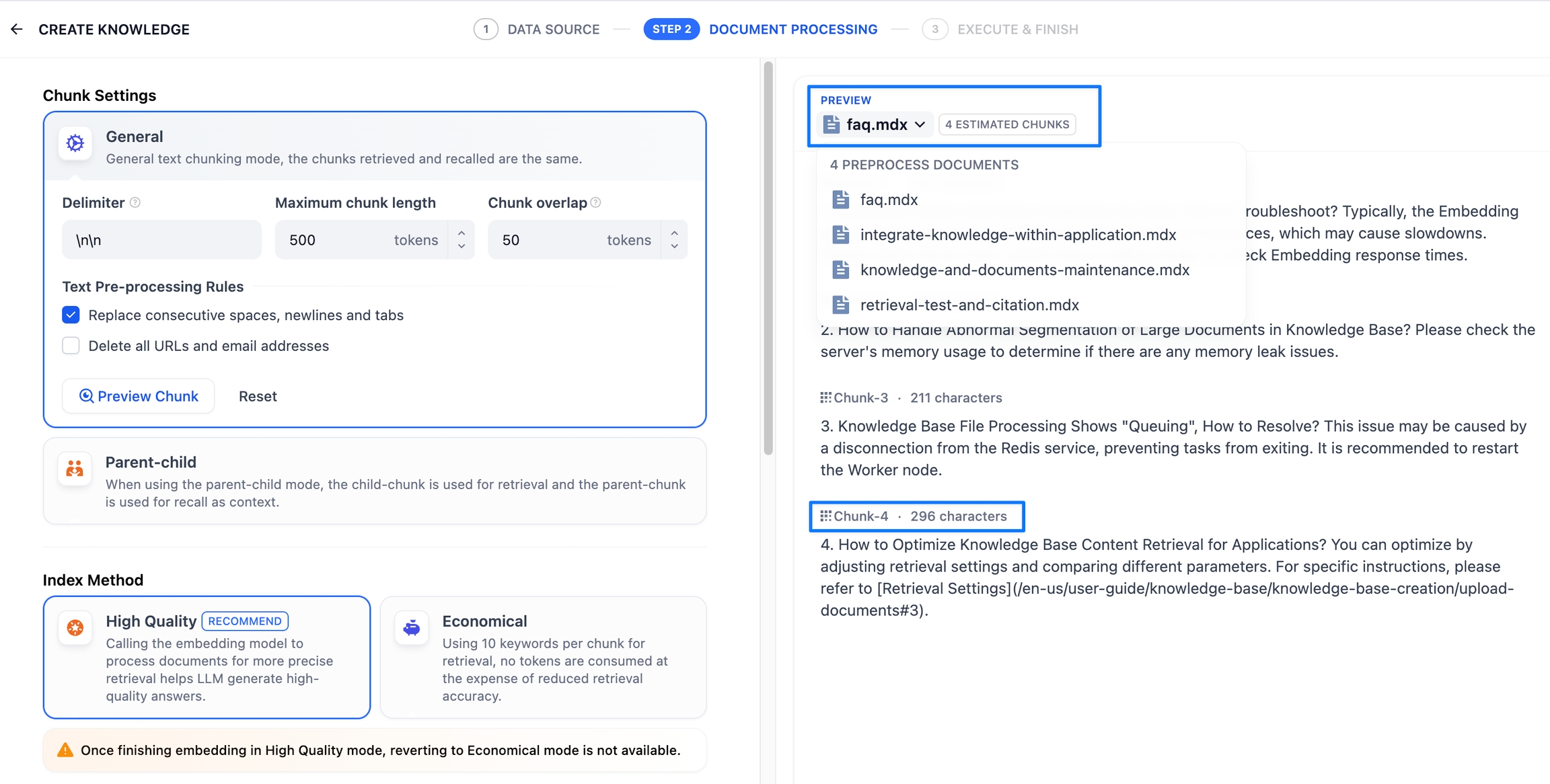
設定完了後、「プレビューブロック」をクリックすることで、セグメント分割後の効果を確認できます。各セグメントの文字数が直感的に理解可能です。
複数の文書を一括でアップロードした場合、文書のタイトルをクリックすることで、他の文書のセグメント分割効果を素早く確認できます。
セグメント分割ルールの設定が完了したら、次にインデックス方式を選択する必要があります。「高品質インデックス」と「経済インデックス」が利用可能で、詳細はインデックス方法の設定をご覧ください。
親子分割モード(階層分割モード)
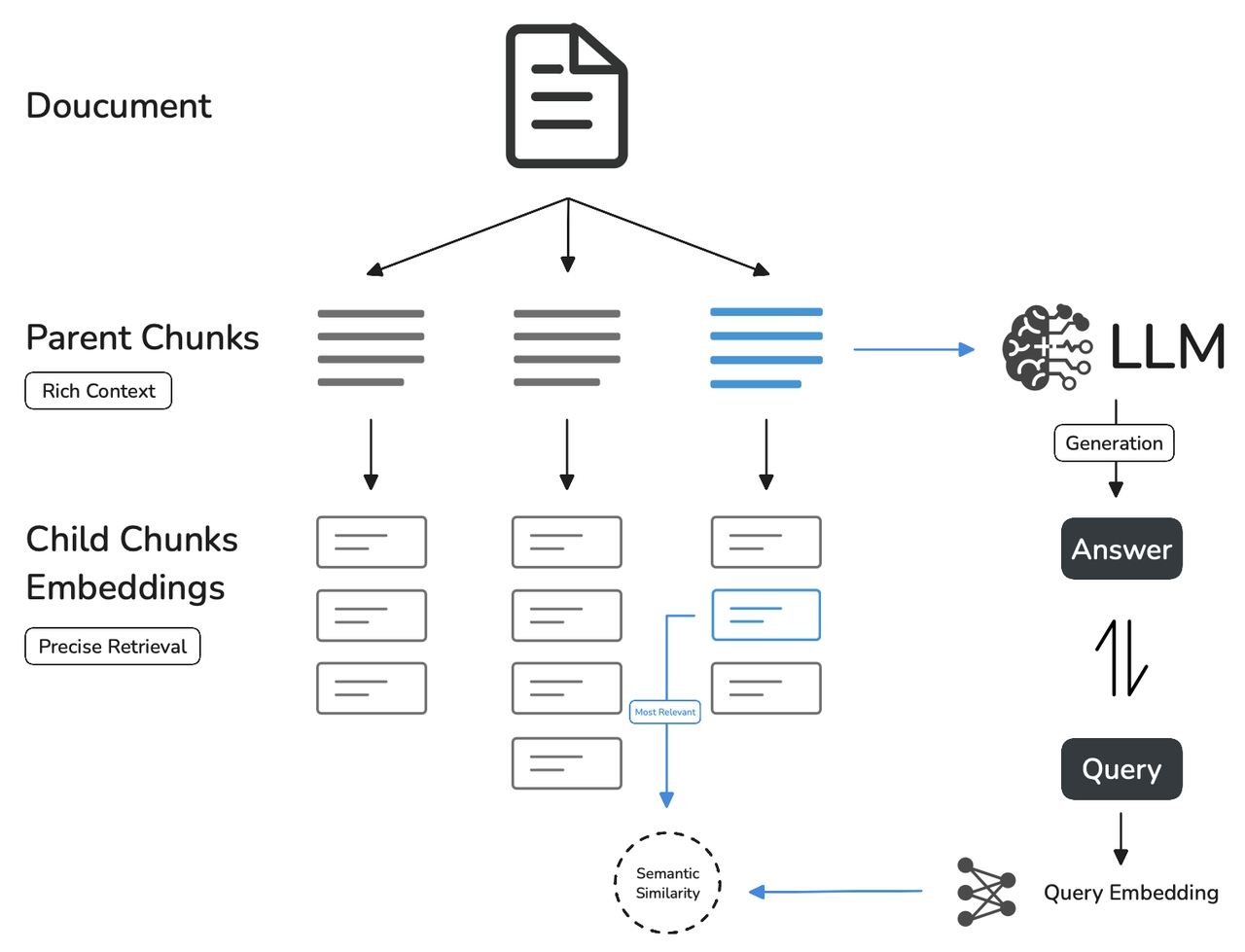
汎用分割モードと比べると、親子分割モードは、データを二層構造で扱うことで、詳細なマッチングと文脈情報の提供の両方を可能にします。例として、AIを活用したカスタマーサポートでは、このモードを用いてユーザーの質問を解決策のドキュメント内の特定の文へと紐づけ、その文が含まれる段落や章をLLMへと送信します。これにより、質問の背景情報を完全に把握し、より適切な回答を提供することができます。
基本的な動作は以下の通りです:
サブセグメントマッチングクエリ:
ドキュメントを小さな情報単位(例えば、一文)に分割し、ユーザーの質問により精密にマッチングします。
サブセグメントは、ユーザーのニーズに最も適した初期結果を素早く提供します。
メインセグメントによる文脈を提供:
マッチングしたサブセグメントを含むより大きな単位(段落、章、または文書全体)をメインブロックとして扱い、LLMへと送信します。
メインセグメントは、LLMが情報を逃さず、ナレッジベースに基づいた適切な回答を導くための完全な背景情報を提供します。
このモードでは、文書の形式やシナリオの要求に応じて、手動で階層型セグメンテーションのルールを設定する必要があります。
メインセグメント(親セグメント):
メインセグメントの設定では、以下のオプションを提供します:
段落 あらかじめ設定された区切り記号ルールと最大ブロック長を基にテキストを段落に分割します。各段落はメインブロックとして扱われ、テキスト量が多く、内容が明確で段落が独立している文書に適しています。以下の設定オプションがあります:
区切り文字、デフォルトは
\nで、テキストの段落に従って分割します。正規表現の文法に従ったカスタムルールを設定でき、テキストに区切り文字が現れたときに自動的に分割します。最大分割長、分割内のテキストの最大文字数を指定し、超えると自動的に分割します。デフォルトは500トークンで、最大4000トークンまで設定可能です。
全文 段落に分けずに、全文を単一のメインブロックとして扱います。パフォーマンスの観点から、テキスト内の最初の10000トークンの文字のみが保持され、テキスト量が少なく、段落間に関連性があり、全文を完全に検索する必要があるシナリオに適しています。

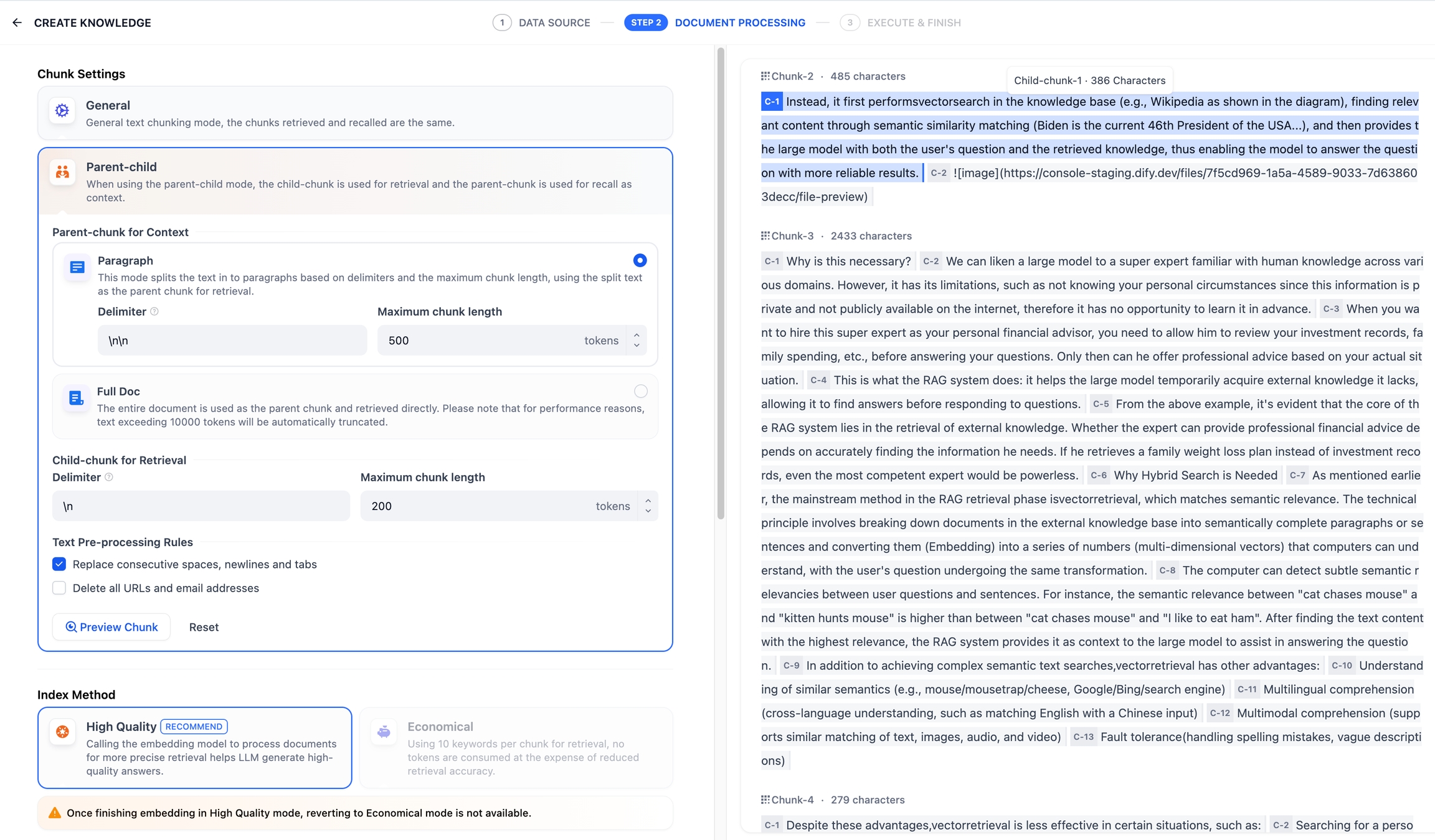
親子分割モードでの段落と全文のプレビュー
サブセグメント(子セグメント):
サブセグメントのテキストは、メインテキストのセグメントに基づいて、区切り記号ルールに従って分割されます。これは、クエリのキーワードに最も関連し、直接的な情報を検索しマッチングするために使用されます。
メインセグメントが段落の場合、サブセグメントはその段落内の個別の文です;メインセグメントが全文の場合、サブセグメントは全文中の各個別の文です。
区切り文字、デフォルトは \n で、文に従って分割します。正規表現の文法に従ったカスタムルールを設定でき、テキストに区切り文字が現れたときに自動的に分割します。
最大分割長、分割内のテキストの最大文字数を指定し、超えると自動的に分割します。デフォルトは200トークンで、最大4000トークンまで設定可能です。
設定完了後、「プレビュー」ボタンをクリックすると、分割された結果を確認できます。メインブロック全体の文字数が確認でき、背景が青色で表示された部分がサブブロックであり、現在のサブセグメントの文字数も表示されます。
分割ルールを変更した場合は、「プレビュー」ボタンを再度クリックして、新しい内容の分割結果を確認する必要があります。
複数の文書を同時にアップロードした場合、ページ上部の文書タイトルをタップして、他の文書へ素早く切り替えて分割結果をプレビューできます。
コンテンツ検索の精度を確保するため、親子分割モードは「高品質インデックス」の使用のみをサポートしています。
二つのモードの主な違いは何ですか?
主な違いは、コンテンツをどのように分割するかにあります。汎用モードでは、複数の独立したブロックにコンテンツが分けられますが、親子モードでは二層構造を使ってコンテンツを分割します。つまり、一つの親ブロック(文書全体や段落)が、複数の子ブロック(文)を含む構造になっています。
この分割方法の違いが、LLMがナレッジベースを検索する際の効率に大きな影響を与えます。特に、親子検索では、より包括的なコンテキスト情報が提供されるため、精度も向上し、従来の単層の汎用検索方法と比べて格段に優れた性能を発揮します。
もっと読む
分割モードを選んだら、次にインデックスの設定や検索方法の調整を行い、ナレッジベースの構築を進めましょう。
検索オプションの設定
Last updated