
エラー処理
著者:アレン、エヴァン
ワークフローアプリは通常、複数の連携する部分(ノード)から成り立っています。どこか一つの部分で発生したエラー(APIリクエストの失敗やLLM出力の問題など)が全体の動作を止めてしまうことがあり、その場合、開発者は故障箇所を見つけて修正するのに大きな労力を費やす必要があります。これは、特に複雑なワークフローの場合には一層の課題となります。
エラー処理メカニズムによって、部分的な問題を様々な方法でうまく対処できるようになります。これにより、一部で問題が発生しても、全体の処理を止めることなくエラー情報を記録したり、別の方法でタスクを完了させることが可能です。アプリケーションの重要な部分にこのメカニズムを取り入れることで、全体の柔軟性と強靭さが大きく向上します。
開発者は、複雑なエラー対応コードを各ノードに書き込む必要がなくなります。また、エラー処理用の追加部分を設けることもなくなります。このメカニズムは、ワークフローの設計をシンプルにし、様々な戦略を用いて実行ロジックを整理します。
実践シナリオ
ネットワークエラーの対応 例えば、あるワークフローが天気情報、ニュース要約、ソーシャルメディア分析の3つのAPIサービスからデータを取得し、それらを統合する必要があるとします。リクエスト制限により一部のサービスが応答しない場合があります。エラー処理を利用して、メインの処理は他のデータソースの処理を続けつつ、失敗したAPI呼び出しの詳細を記録します。これにより開発者は後からこれらの情報を分析し、サービス呼び出しの戦略を改善することができます。
ワークフローの代替ルート たとえば、あるLLMノードが詳細なドキュメントの要約を行う際に、入力が長すぎてトークン制限を超えてしまい、エラーが発生することがあります。エラー処理メカニズムを設定することで、このような状況に遭遇した際には、内容を小分けにして処理を続ける代替ルートを自動的に選択でき、処理の中断を避けることができます。
エラー情報の明確化 実行中にあいまいなエラーメッセージ(「呼び出し失敗」など)が返されると、問題の特定が難しくなることがあります。エラー処理メカニズムにより、開発者はエラーメッセージを事前に定義することができ、デバッグ時により明確で正確な情報を提供することが可能になります。
エラー処理メカニズムの活用
以下の4つのノードタイプにエラー処理メカニズムを組み込むことで、より詳細なドキュメントを参照し、アプリを強化することができます:
失敗後の再試行
特定の例外状況では、ノードの再試行操作によって問題を解決できる場合があります。このような場合には、ノードの「失敗後の再試行」機能を有効化し、再試行の最大回数と間隔を指定することが可能です。
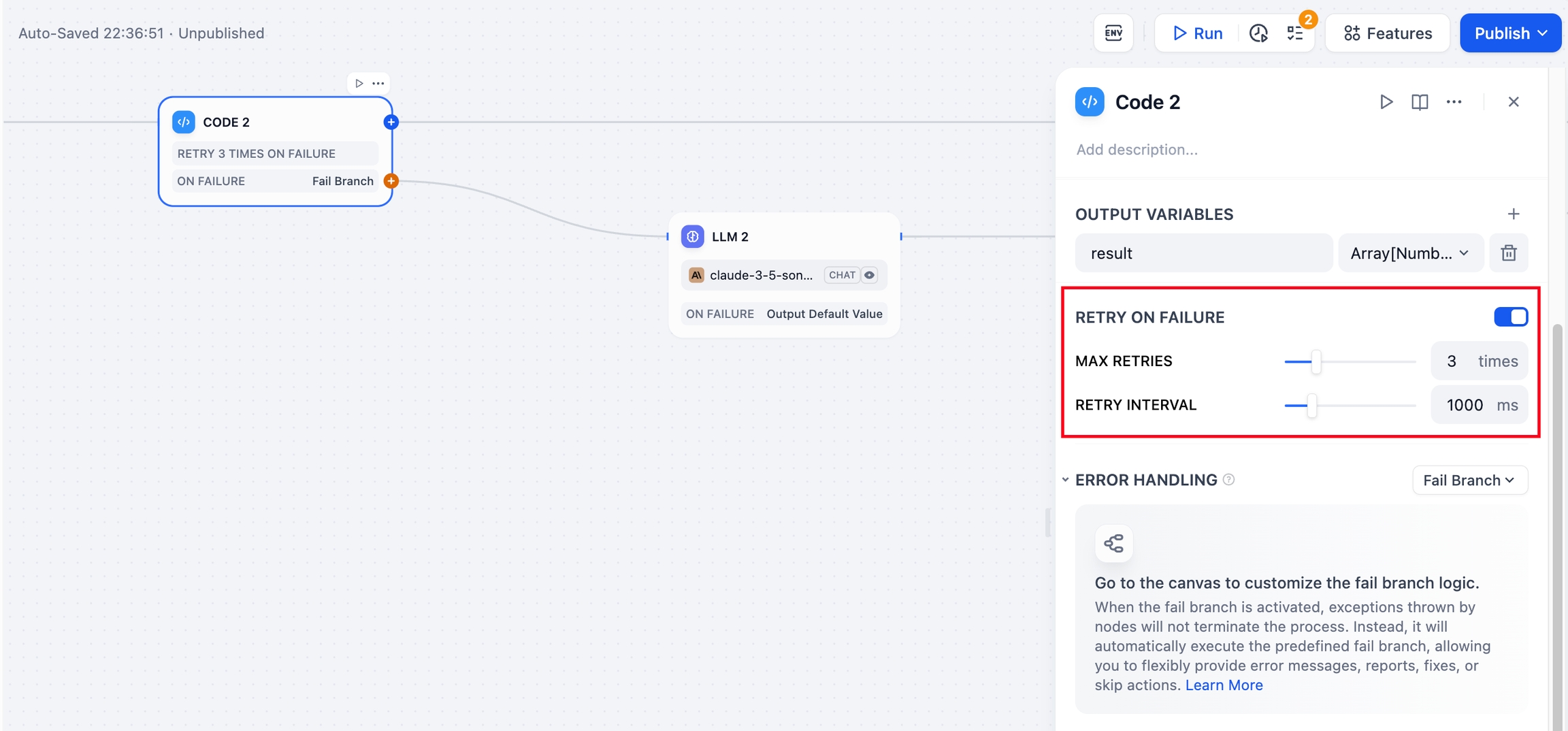
もしノードの再試行を行ってもエラーが続く場合、エラー処理機能が予め定められた対策に従って次の手順を進めます。
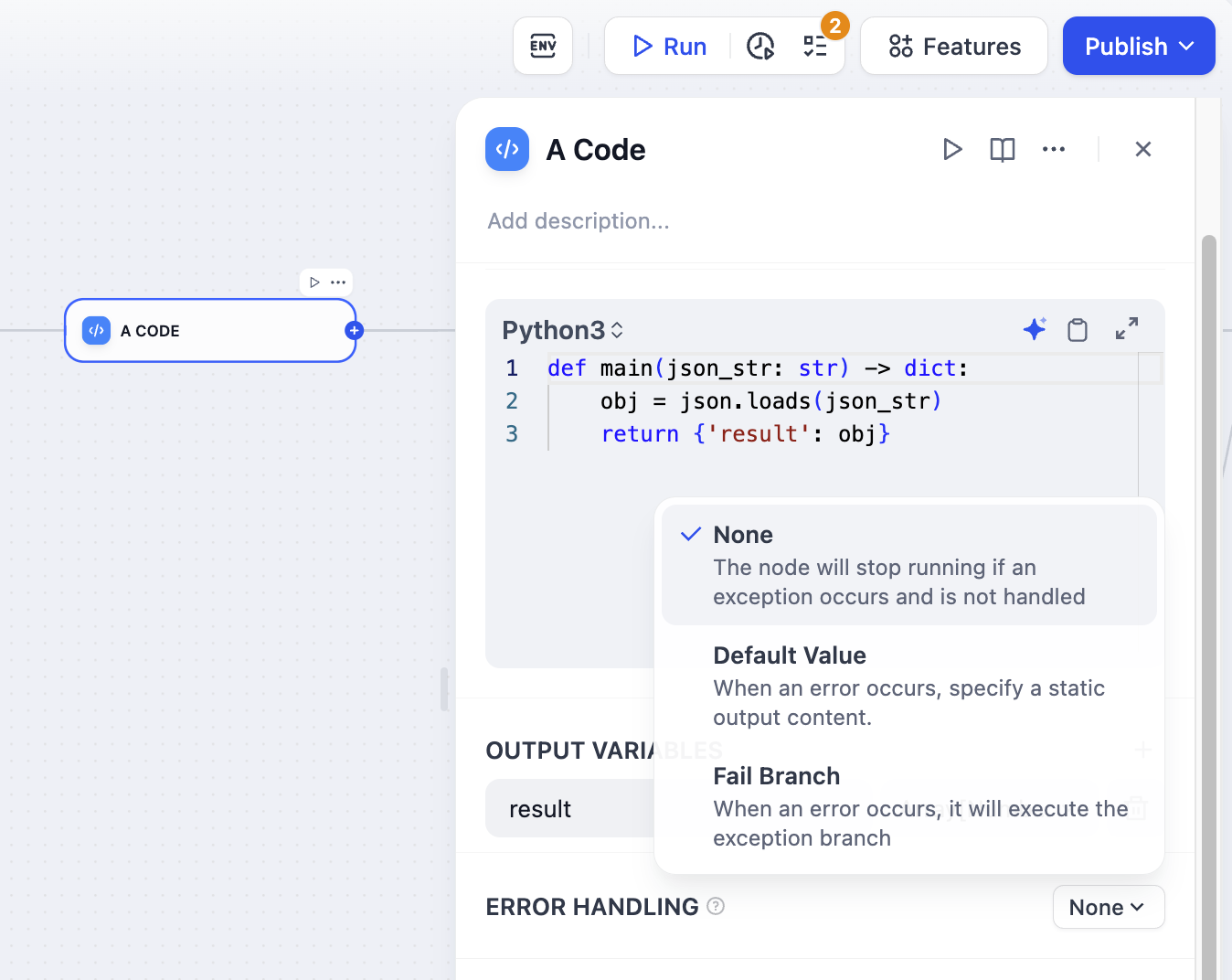
エラー処理
異常処理の仕組みには、次の3つの選択肢があります:
処理なし:エラーを処理せずに、ノードからのエラーメッセージをそのまま返し、フロー全体を停止します。
デフォルト値:開発者がエラー情報をあらかじめ定義できるようにします。エラーが発生した場合、定義された値によって元のノードが返すエラー情報を置き換えます。
エラーブランチ:エラーが発生した場合、あらかじめ設定されたエラー処理のブランチを実行します。
各処理方法の詳細と設定方法については、事前定義されたエラー処理ロジックをご覧ください。
スタートアップガイド
シナリオ:ワークフローアプリにエラー処理メカニズムを追加する
以下は、ワークフローアプリで異常処理メカニズムを設定し、ノードの異常に備えて代替処理を行う方法の簡単な例です。
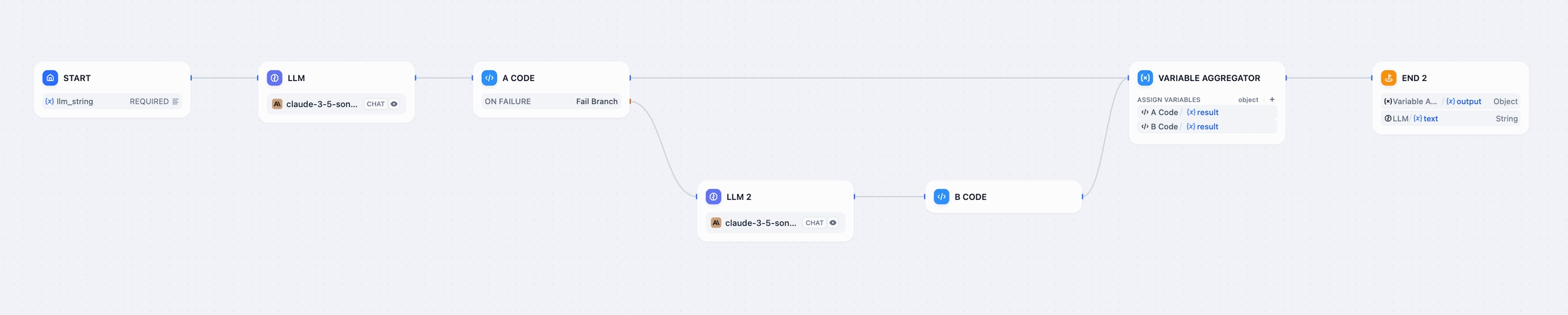
アプリのロジック:LLMノードは入力された指示に従って、正しい形式や間違った形式のJSONコードを生成します。その後、Aコードノードがこのコードを実行し結果を出力します。Aコードノードが誤った形式のJSONコンテンツを受け取った場合には、設定された異常処理メカニズムに基づいて、代替パスを実行しメインプロセスを継続します。
1. JSONコード生成ノードの設定
新しいワークフローアプリを作成し、LLMノードとコードノードを追加します。プロンプトを使ってLLMが指示に従い、正しい形式や間違った形式のJSONコンテンツを生成し、それがAコードノードで検証されます。
LLMノードでのプロンプト例:
コードノードでのJSON検証コード:
2. Aコードノードにエラー処理機能を追加する
Aコードノードは、JSONコンテンツを検証する役割を持ち、受け取ったJSONコンテンツがフォーマットに合わない場合には、エラー処理機能を通じて代替の手順を踏み、エラーを修正するために次のLLMノードに渡します。その後、JSONを再度検証し、メインの処理フローを再開します。Aコードノードの「エラー処理」タブから「エラー分岐」の設定を行い、新たなLLMノードを設定しましょう。
3. Aコードノードが出力するエラーの内容を修正
新設したLLMノードでは、プロンプトに指示を記述し、変数を用いてAコードノードが出力したエラー内容を参照・修正します。次に、Bコードノードを追加し、JSONコンテンツの再検証を行います。
4. プロセスの完了
変数を集約するノードを追加して、正常な処理結果とエラー処理結果をまとめ、終了ノードで出力します。これでフロー全体のプロセスが完了します。
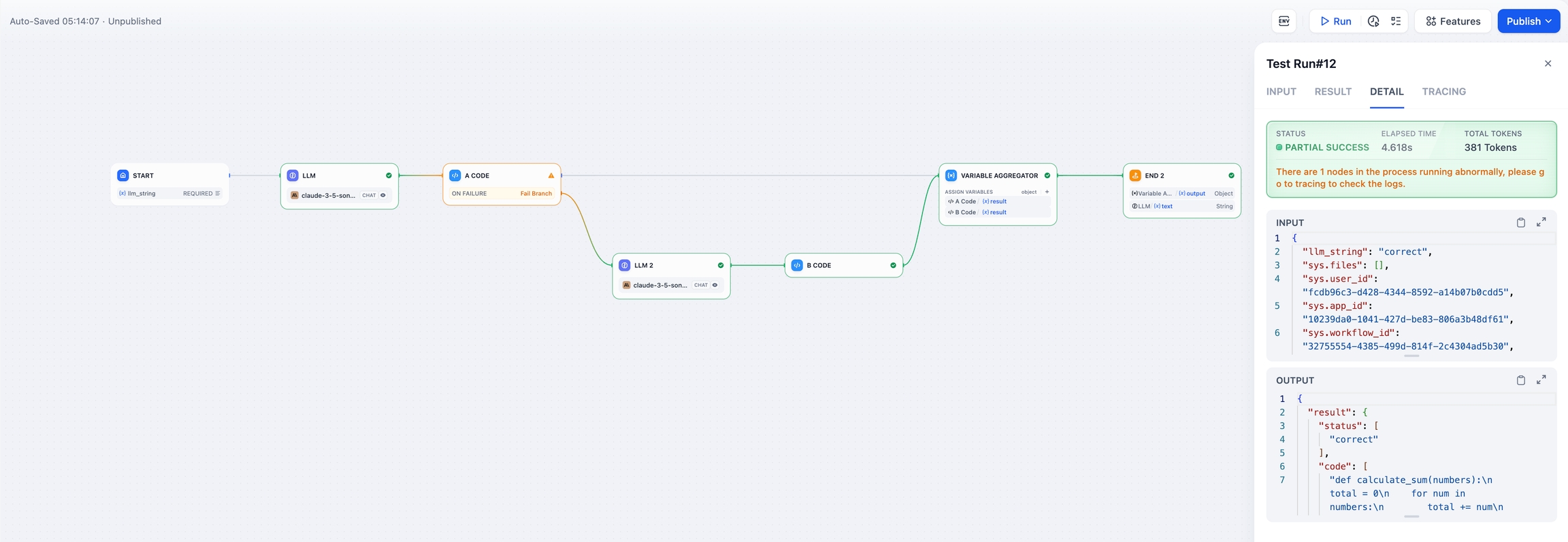
デモ用のDSLファイルはこちらからダウンロードできます。
ステータス説明
この文書では、ノードとプロセスの状態について説明します。状態を明確にすることで、開発者は現在のワークフローアプリケーションの動作状況を理解しやすくなり、問題解決や迅速な意思決定に役立ちます。エラー処理機能を導入したことにより、ノードとプロセスの状態には以下のような分類があります:
ノードの状態
成功 ノードが正常に動作して正確な情報を出力しました。
失敗 エラー処理が行われず、ノードの動作が失敗し、エラー情報が出力されました。
エラー ノードでエラーが発生しましたが、処理が継続されました。
ワークフローの状態
成功 プロセスの全ノードが正常に動作し、終了ノードが適切に情報を出力し、ステータスが成功として設定されました。
失敗 ノードでエラーが発生し、プロセス全体が停止し、ステータスが失敗として設定されました。
部分成功 ノードでエラーが発生しましたが、エラー処理機能によってプロセス全体が最終的に正常に動作しました。ステータスは部分成功として設定されました。
よくある質問
1. エラー処理機構を導入することで何が変わりますか?
エラー処理機構がない場合:
作業フローが中断する:外部のサービス呼び出しに失敗する、ネットワークに問題がある、ツールにエラーが存在するなどの理由で、一つのエラーが発生すると、作業フローが即座に停止します。開発者はエラーを手動で探し出し、修正後に作業フローを再開する必要があります。
対応策の制約:開発者は異なるエラータイプや事象に応じて特別な対応策を講じることができません。たとえば、エラーが発生した場合にもフローを継続する、または別の処理へ切り替えるといったことができなくなります。
冗長なノードの手動追加が必要:エラーがフロー全体に影響を与えないようにするためには、エラーを捉えて処理するために多くの追加ノードを設計する必要があり、これが作業フローの複雑さや開発コストを増加させます。
限られたログ情報:エラーログは通常、内容が簡素であったり、必要な情報が不足していたりします。これでは問題の迅速な診断が難しくなります。
エラー処理機構を導入した後:
フローが中断されることがない:あるノードでエラーが発生しても、事前に定めたルールに従って作業フローを継続することができ、一点の障害が全体に影響することが少なくなります。
エラー処理を柔軟にカスタマイズ可能:開発者はそれぞれのノードごとにエラー対応の戦略を設定できます。例えば、フローを継続したり、ログを残したり、別のルートに切り替えたりすることができます。
作業フローの設計をシンプルに:一般的なエラー処理機構により、開発者が冗長なノードを手動で設計する必要が減り、作業フローがよりシンプルで明瞭になります。
詳細なエラーログを提供:カスタマイズ可能なエラー情報の整理メカニズムを提供し、開発者が問題を迅速に特定し、フローを最適化するのに役立ちます。
2. 代替ルートの実行状況をどうやってデバッグしますか?
作業フローの実行ログをチェックすることで、条件分岐やルート選択の状況を確認できます。エラー処理のブランチは黄色でハイライトされ、開発者が計画通りに代替ルートが実行されているかどうかを簡単に確認できます。
Last updated