
モデルプロバイダーの構築
Modelタイプのプラグインを作成する最初のステップは、プラグインプロジェクトを初期化し、モデルプロバイダーファイルを作成することです。その後、具体的な定義済みモデルやカスタムモデルを接続します。
事前準備
Difyプラグインのスキャフォールディングツール
Python環境(バージョン3.12以上)
プラグイン開発用のスキャフォールディングツールの準備方法については、開発ツールの初期化を参照してください。
新規プロジェクトの作成
スキャフォールディングツールのコマンドラインから、新しいDifyプラグインプロジェクトを作成します。
./dify-plugin-darwin-arm64 plugin initこのバイナリファイルをdifyにリネームし、/usr/local/binにコピーした場合は、次のコマンドで新しいプラグインプロジェクトを作成できます。
dify plugin initモデルプラグインテンプレートの選択
スキャフォールディングツール内のすべてのテンプレートには、必要なコードが全て含まれています。LLMタイプのプラグインテンプレートを選択してください。
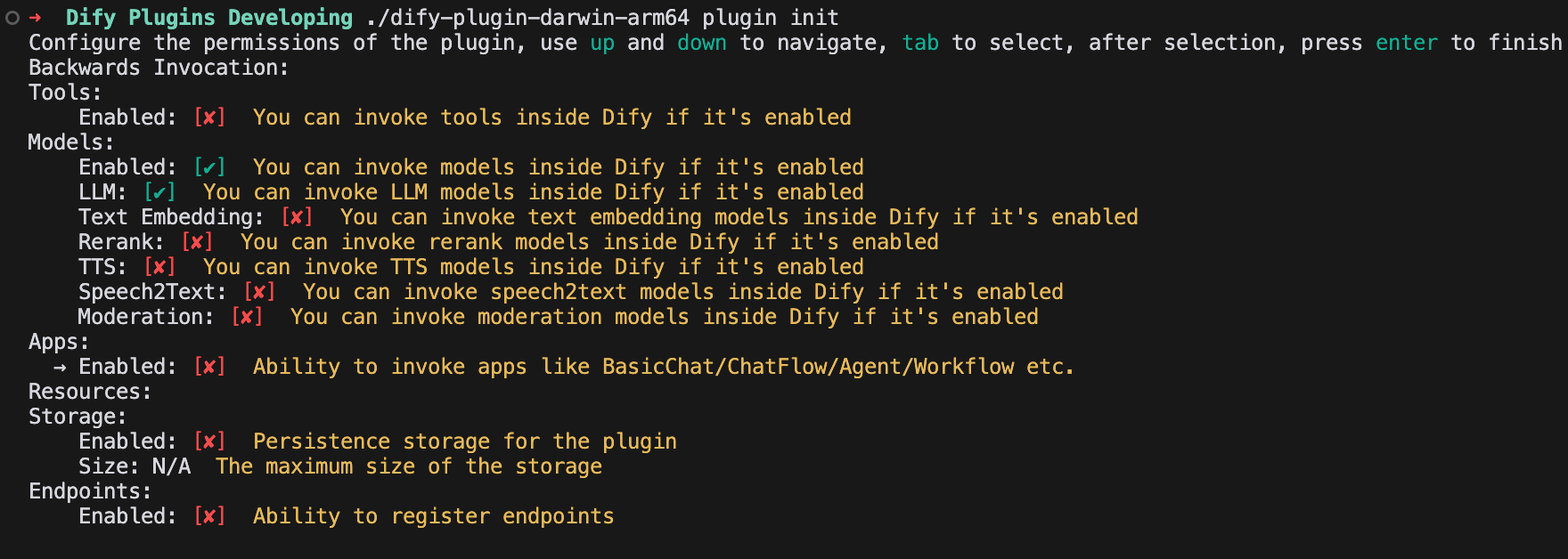
プラグイン権限の設定
このLLMプラグインには、次の権限を設定します。
Models
LLM
Storage
モデルタイプ設定の説明
モデルプロバイダーは、以下の2つのモデル設定方法をサポートしています。
predefined-model定義済みモデル一般的な大規模モデルタイプで、統一されたプロバイダー認証情報を設定するだけで、モデルプロバイダーが提供する定義済みモデルを利用できます。たとえば、
OpenAIモデルプロバイダーは、gpt-3.5-turbo-0125やgpt-4o-2024-05-13など、様々な定義済みモデルを提供しています。詳細な開発手順については、定義済みモデルの接続を参照してください。customizable-modelカスタムモデル各モデルの認証情報設定を手動で追加する必要があります。たとえば、
XinferenceはLLMとText Embeddingの両方をサポートしていますが、各モデルには一意のmodel_uidがあります。両方を同時に接続する場合は、各モデルにmodel_uidを設定する必要があります。詳細な開発手順については、カスタムモデルの接続を参照してください。
これら2つの設定方法は共存可能です。つまり、プロバイダーがpredefined-modelとcustomizable-modelの両方、またはpredefined-modelのみをサポートしている場合、プロバイダーの統一認証情報を設定することで、定義済みモデルとリモートから取得したモデルを使用できます。さらに、新しいモデルを追加した場合は、それに基づいてカスタムモデルを使用することも可能です。
新しいモデルプロバイダーの追加
新しいモデルプロバイダーを追加するには、主に次の手順が必要です。
モデルプロバイダー設定YAMLファイルの作成
プロバイダーディレクトリにYAMLファイルを追加し、プロバイダーの基本情報とパラメータ設定を記述します。ProviderSchemaの要件に従って記述し、システムの仕様との整合性を確保してください。
モデルプロバイダーコードの記述
プロバイダークラスのコードを作成します。システムのインターフェース要件に準拠したPythonクラスを実装して、プロバイダーのAPIに接続し、コア機能を実装します。
以下は、各ステップの詳細な操作手順です。
1. モデルプロバイダー設定ファイルの作成
ManifestはYAML形式のファイルで、モデルプロバイダーの基本情報、サポートされているモデルタイプ、設定方法、認証情報ルールを定義します。プラグインプロジェクトのテンプレートには、/providersパスに設定ファイルが自動的に生成されます。
以下は、Anthropicモデルの設定ファイルanthropic.yamlのサンプルコードです。
接続するプロバイダーがカスタムモデル(たとえば、OpenAIがファインチューニングモデルを提供する場合)を提供する場合は、model_credential_schemaフィールドを追加する必要があります。
以下は、OpenAIファミリーモデルのサンプルコードです。
より詳細なモデルプロバイダーYAMLの仕様については、モデルインターフェースドキュメントを参照してください。
2. モデルプロバイダーコードの記述
/providersフォルダに、同じ名前のPythonファイル(たとえば、anthropic.py)を作成し、__base.provider.Provider基本クラス(たとえば、AnthropicProvider)を継承するclassを実装します。
以下は、Anthropicのサンプルコードです。
プロバイダーは、__base.model_provider.ModelProvider基底クラスを継承し、validate_provider_credentialsプロバイダー統一認証情報検証メソッドを実装する必要があります。
もちろん、validate_provider_credentialsの実装を後回しにして、モデル認証情報検証メソッドの実装後に直接再利用することもできます。
カスタムモデルプロバイダー
他のタイプのモデルプロバイダーについては、以下の設定方法を参照してください。
Xinferenceのようなカスタムモデルプロバイダーの場合、完全な実装手順を省略できます。XinferenceProviderという名前の空のクラスを作成し、その中に空のvalidate_provider_credentialsメソッドを実装するだけで済みます。
詳細説明:
XinferenceProviderは、カスタムモデルプロバイダーを識別するためのプレースホルダーとして機能します。validate_provider_credentialsメソッドは実際には呼び出されませんが、親クラスが抽象クラスであるため、すべてのサブクラスがこのメソッドを実装する必要があります。空の実装を提供することで、抽象メソッドが実装されていないことによるインスタンス化エラーを回避できます。
モデルプロバイダーを初期化した後、プロバイダーが提供する具体的なLLMモデルを接続する必要があります。詳細については、以下を参照してください。
Last updated