
変数代入
定義
変数代入ノードは、書き込み可能な変数に他の変数を代入するために使用されます。現在、サポートされている可書き入れの変数は:
使用方法:このノードを使用することで、ワークフローの中で変数の値を会話変数に一時的に保存し、後続の会話でその値を参照することができます。
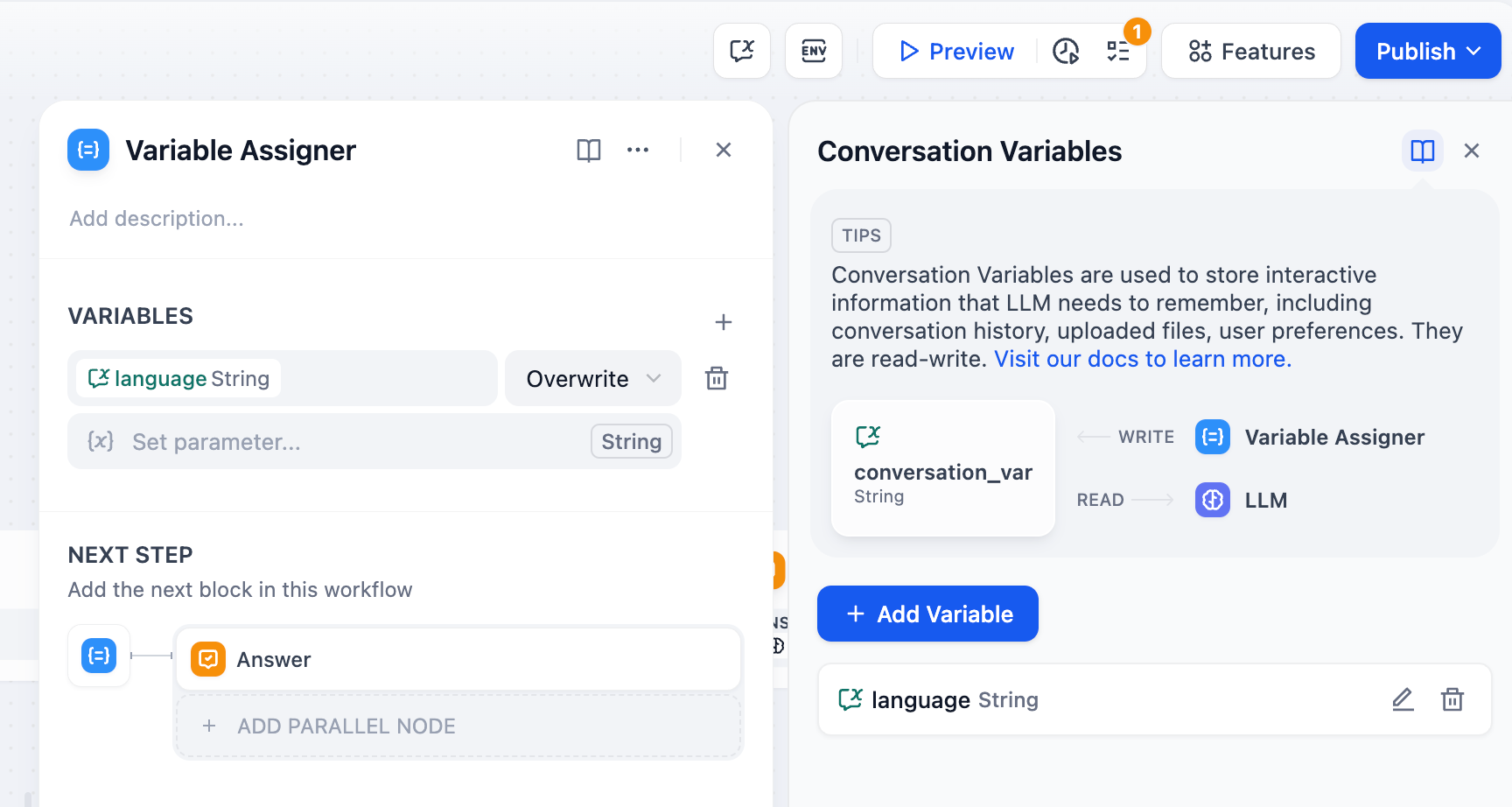
使用シナリオの例
変数代入ノードを活用することで、会話中のコンテキスト、ダイアログにアップロードされたファイル、ユーザーの好みの情報などを会話変数に書き込み、保存された情報は後続の会話で参照され、異なる処理フローに誘導したり、返答を行ったりすることができます。
シナリオ 1
会話中の記録を自動的に抽出し保存します、会話変数配列を使用してユーザーの重要な情報を記録します。その後の会話ではこれらの記録を活用し、個別の返信を行います。
例えば:会話が始まると、LLMはユーザーの入力に必要な情報や好み、またはチャット履歴が含まれているかを自動的に判断します。情報が存在する場合、LLMはそれを先に抽出して保存し、コンテキストとして利用して応答します。もし新しい情報を覚える必要がない場合、LLMは以前の関連する記録を用いて個性化な応答を出します。

設定手順:
会話変数を設定:まず、会話変数配列
memoriesを設定し、array[object]型を持たせてユーザーの事実、好み、会話記録を保存します。記録の判断と抽出:
条件判断ノードを追加し、LLMを使用してユーザーの入力に新しい情報が含まれているかを判断します。
新しい情報がある場合は上流に進み、LLMノードを使用してこれらの情報を抽出します。
新しい情報がない場合は下流に進み、既存の記憶を直接使用して返答します。
変数の代入と書き込み:
上流に進んだ後、変数代入ノードを用いて抽出した新しい情報を
memories配列に追加(append)します。LLMの出力テキスト文字列を適切な array[object] 形式に変換するためにエスケープ機能を使用します。
変数の読み取りと利用:
後続のLLMノードで、
memories配列の内容を文字列に変換し、LLMのプロンプトにコンテキストとして挿入します。LLMはこれらの記憶を使用して個別の返信を生成します。
図中のcodeノードのコードは以下の通りです:
文字列をオブジェクトに変換する
オブジェクトを文字列に変換する
シナリオ 2
ユーザーの初期の好み情報を記録し,会話中にユーザーが入力した言語の好みを記憶し、後続の会話でその言語を使用して返信します。
例:ユーザーが会話を始める前に、language入力欄に「日本語」と指定した場合、その言語は会話変数に書き込まれ、LLMは後続の返信時に会話変数の情報を参照し、継続的に「日本語」を使用して返信します。

設定手順:
会話変数の設定:まず、会話変数 language を設定し、会話の開始時にこの変数の値が空かどうかを判断する条件分岐ノードを追加します。
変数の書き込み/代入:最初の会話が開始された際、 language 変数の値が空であれば、LLMノードを使用してユーザーの言語入力を抽出し、その言語タイプを会話変数 language に書き込みます。
変数の読み取り:後続の会話ラウンドでは、language 変数にユーザーの好みの言語が保存されています。以降の会話では、LLMノードがこの変数を参照し、ユーザーの好みの言語タイプを用いて返信します。
シナリオ 3
Checklistのチェックを補助し、会話中に会話変数にユーザーの入力項目を記録し、Checklistの内容を更新し、後続の会話で抜け漏れ項目を確認します。
例:会話を始める際、LLMはユーザーにチェックリストに関連するアイテムの入力を求めます。ユーザーがチェックリストの内容を一度述べると、その内容は会話変数に更新され、及び保存されます。LLMは各会話の後に、ユーザーに不足しているアイテムの追加を促します。

配置流程:
会話変数の設定:最初に会話変数
ai_checklistを設定し、これをLLM内でチェックのコンテクストとして参照します。変数の書き込み/代入:各会話のラウンドごとに、LLMノード内の
ai_checklistの値を確認し、ユーザーの入力と比較します。ユーザーが新しい情報を提供した場合、チェックリストを更新し、変数代入ノードを使用して出力内容をai_checklistに書き込みます。変数の読み取り:
ai_checklistの値を読み取り、すべてのチェックリストアイテムが完了するまで、各会話のラウンドでユーザーの入力と比較します。
3 操作方法
変数代入の使用:
右側にある「+」アイコンをクリックし、「変数の代入」ノードを選びます。代入された変数と、その変数に値を提供するソース変数を設定してください。このノードを用いることで、一度に複数の変数へ値を割り当てることが可能です。
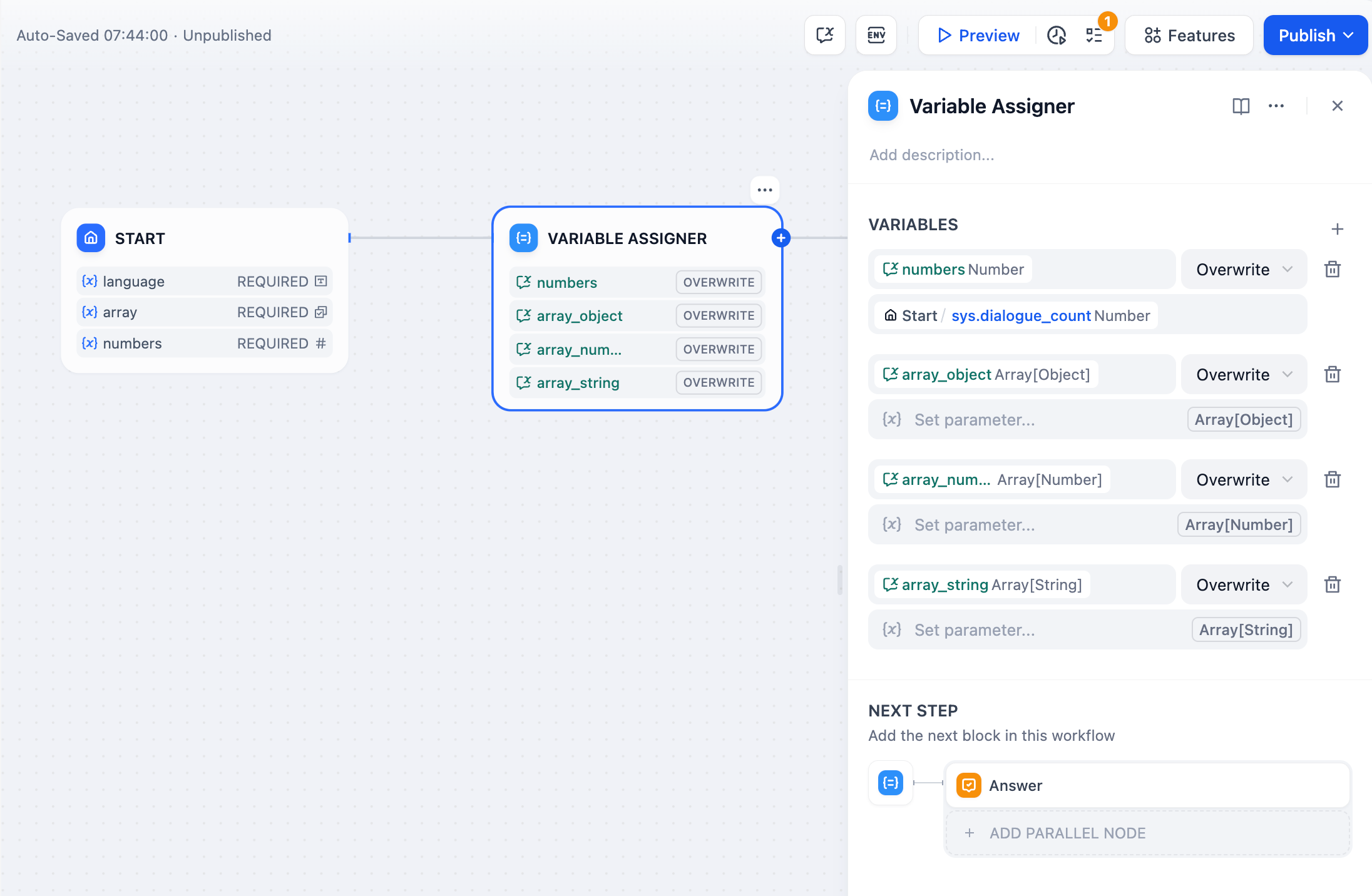
変数の設定方法:
変数: 値を割り当てる対象の変数を選択します。これは、値を設定したい対話変数です。
ソース変数を設定: 値の出典となる変数を選択します。これは、割り当てる値を持っている変数です。
上の画像では、ユーザーが初期ページ Start/language で選択した言語の好みを、システムレベルの対話変数 language に割り当てる流れが示されています。
変数を設定する際の操作モード
対象変数のデータタイプに応じて、操作方法が異なります。以下に、異なるデータタイプの変数に対する操作モードを紹介します:
文字列型(String)の変数の場合:
上書き(Overwrite): ソース変数の値で対象変数の値を直接置き換えます。
クリア(Clear): 対象変数の値を削除します。
設定(Set): 手動で値を入力して対象変数に割り当てます。
数値型(Number)の変数の場合:
上書き(Overwrite): ソース変数の値で対象変数の値を直接置き換えます。
クリア(Clear): 対象変数の値を削除します。
設定(Set): 手動で値を入力して対象変数に割り当てます。
算術(Arithmetic): 対象変数に対して、足し算、引き算、掛け算、または割り算を行います。
オブジェクト型(Object)の変数の場合:
上書き(Overwrite): ソース変数の値で対象変数の値を直接置き換えます。
クリア(Clear): 対象変数の値を削除します。
設定(Set): 手動で値を入力して対象変数に割り当てます。
配列型(Array)の変数の場合:
上書き(Overwrite): ソース変数の値で対象変数の値を直接置き換えます。
クリア(Clear): 対象変数の値を削除します。
追加(Append): 対象変数の配列に新しい要素を追加します。
拡張(Extend): 新しい配列を対象変数に追加し、一度に複数の要素を追加することができます。
Last updated