
ナレッジベース内ドキュメントの管理
ナレッジベース内のドキュメントの編集
ドキュメントの追加
ナレッジベースは複数のドキュメントから構成されています。ドキュメントは、ローカルからのアップロードのほか、他のオンラインデータソースからのインポートにも対応しています。ナレッジベース内の各ドキュメントは、データソース上の “1ファイル” に相当し、たとえば Notion 内の1件のドキュメントや、Web上のオンラインドキュメントなどが該当します。
既に作成済みのナレッジベースに新たなドキュメントを追加するには、「ナレッジベース」 → 「ドキュメント一覧」 → 「ファイル追加」をクリックしてください。

ドキュメントの有効化/無効化/アーカイブ/削除
有効化:通常使用可能な状態のドキュメントは、編集およびナレッジベース内での検索が可能です。無効化されたドキュメントは後から再び有効化できます。また、一度アーカイブされたドキュメントは、アーカイブ解除後にのみ再有効化が可能となります。
無効化:AIアプリケーション利用時に検索対象から除外したいドキュメントについては、該当ドキュメント右側にある青いスイッチをオフにすることで無効化できます。なお、無効化後も内容の編集は可能です。
アーカイブ:今後削除せずに保存しておきたい古いドキュメントの場合、アーカイブ機能をご利用ください。アーカイブされたドキュメントは閲覧や削除は可能ですが、再編集はできません。アーカイブは、ナレッジベースのドキュメント一覧から該当ボタンをクリックするか、ドキュメント詳細画面から操作できます。アーカイブ操作は後から取り消し可能です。
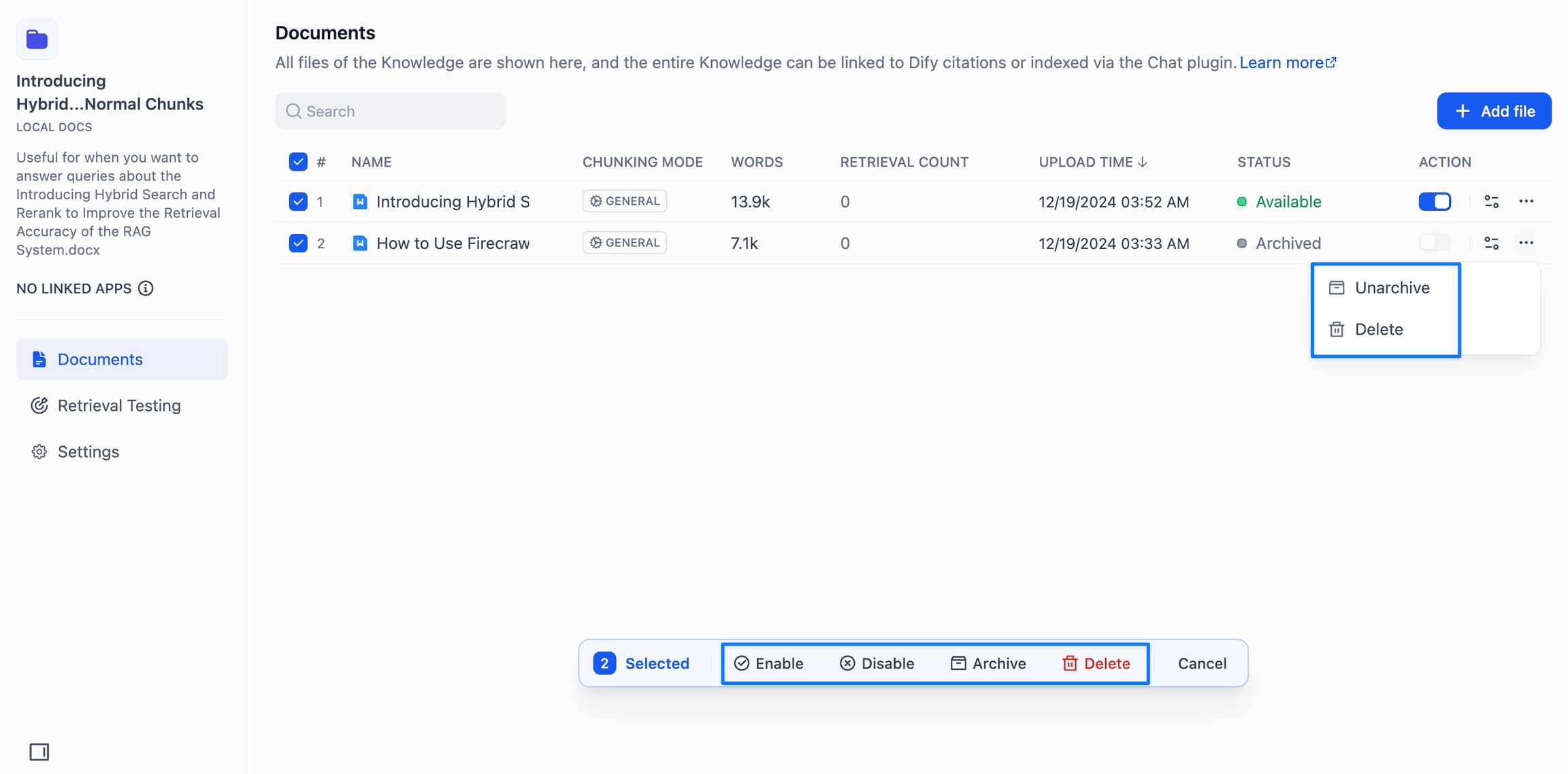
削除:⚠️ 削除は取り消し不可能なため、誤ったドキュメントや内容が曖昧なものについては、ドキュメント右側のメニューから削除してください。削除したドキュメントは復元できませんので、慎重に操作してください。
上記の各操作は、複数のドキュメントを同時に選択した状態で一括実行することも可能です。
注意:
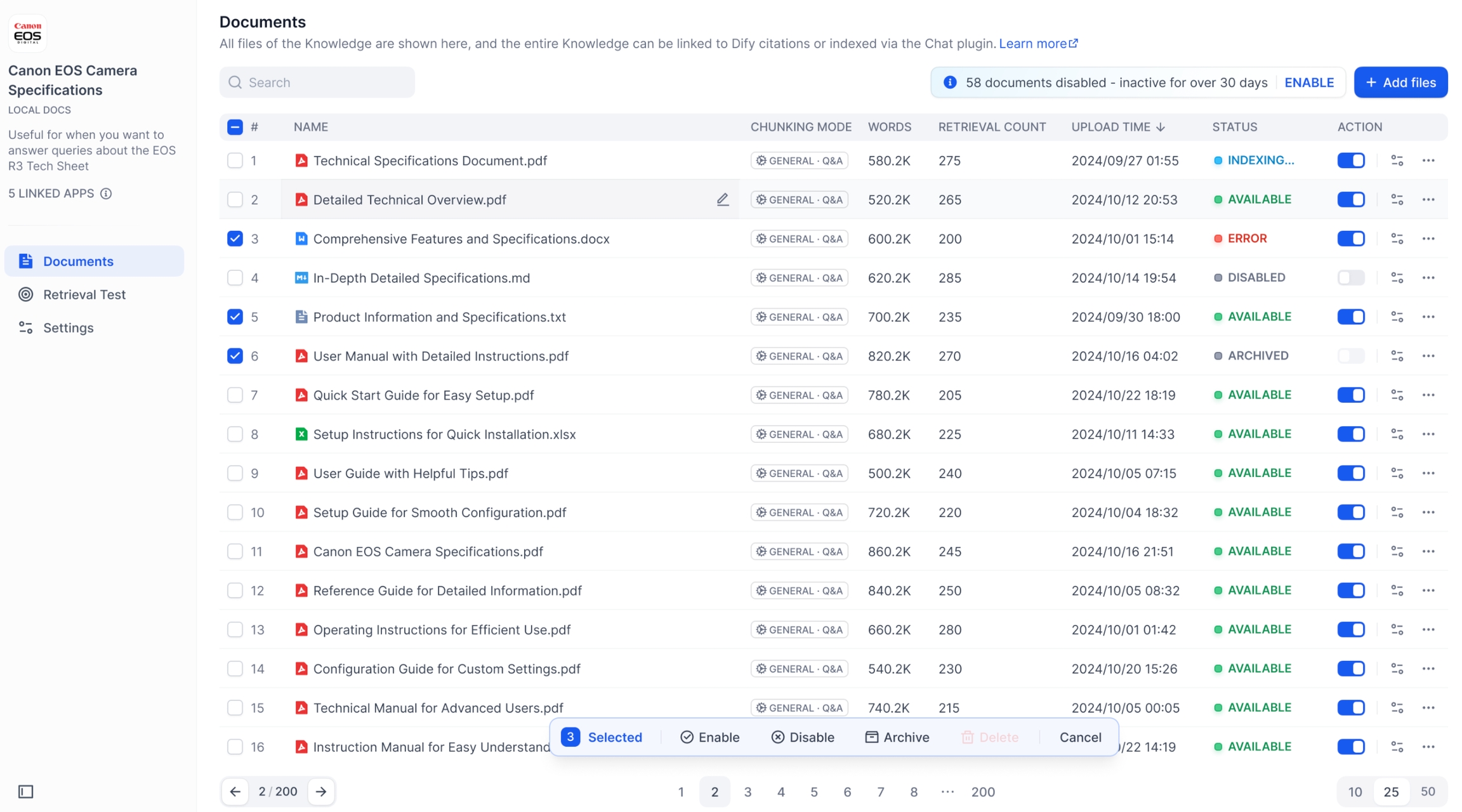
ナレッジベース内で長期間更新がなく、または検索対象とならなかったドキュメントについては、システムの効率運用を考慮し、一時的に無効化される場合があります。
Sandbox/Free プランのユーザーでは、利用されていないナレッジベース内のドキュメントは 7日後 に自動で無効化されます。
Professional/Team プランのユーザーでは、同様のドキュメントが 30日後 に自動で無効化されます。
いつでもナレッジベースへアクセスし、再度有効化することで通常利用に戻すことが可能です。なお、料金プランをご利用のユーザーは 「一括復元」 機能によって、無効化された全ドキュメントを迅速に有効化できます。
テキスト分割の管理
テキスト分割の表示
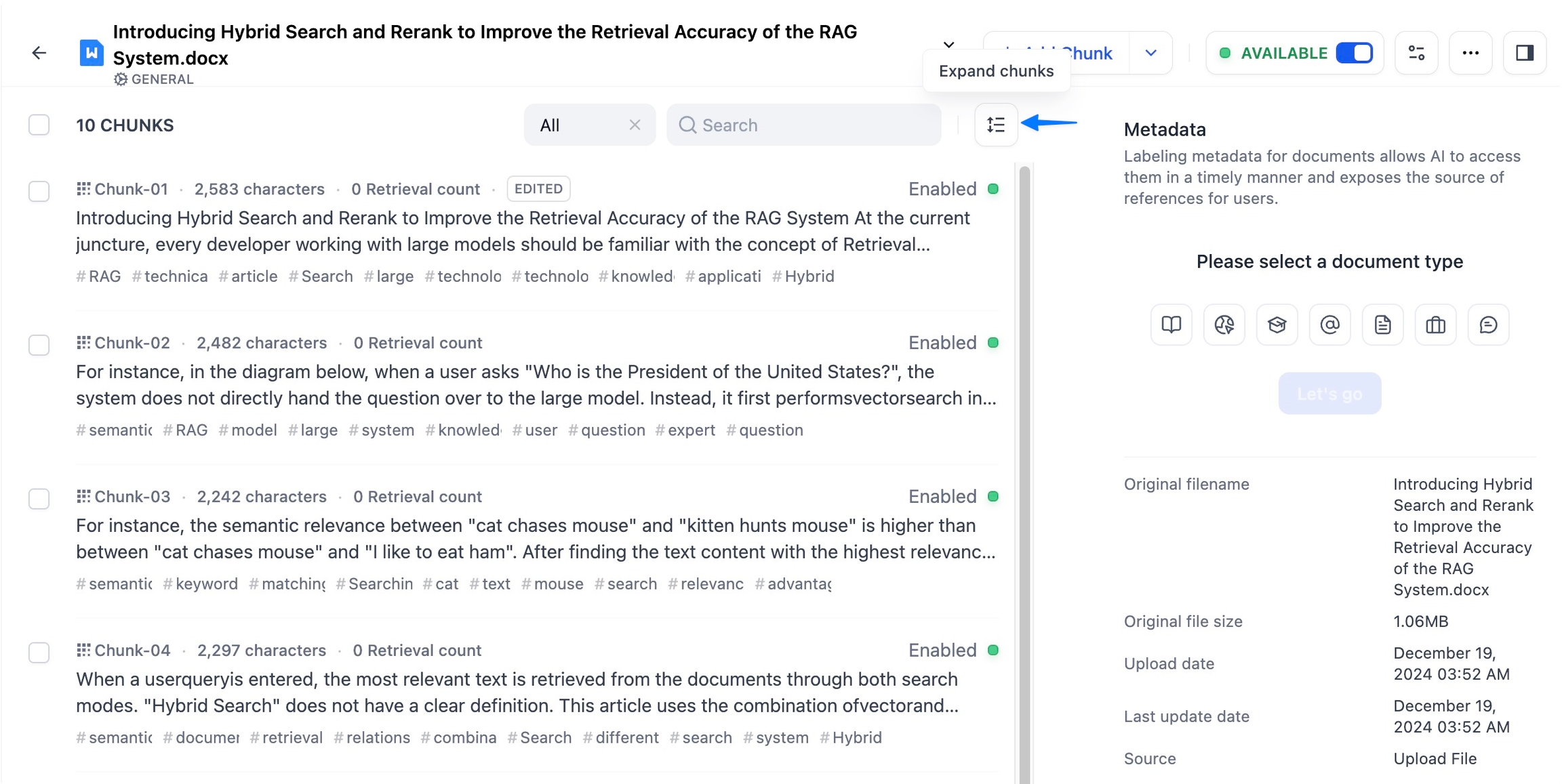
ナレッジベースにアップロードされた各ドキュメントは、テキスト分割(Chunks)形式で格納されます。ドキュメントタイトルをクリックすると、詳細画面でそのドキュメントの分割リストが表示され、初期状態では1ページにつき10のブロックが表示されます。ページ下部の設定にて、1ページあたりの表示件数を調整可能です。
各ブロックは、先頭2行のプレビューを提示します。ブロック内の全内容を確認したい場合は、「分割を展開」ボタンをクリックしてください。
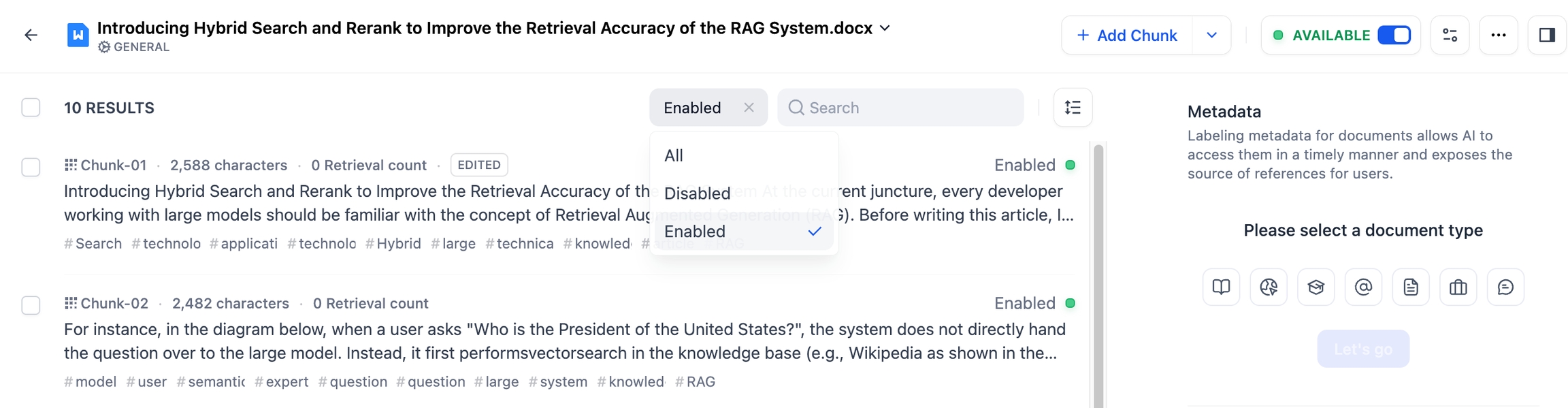
また、フィルター機能を利用することで、有効/無効状態のドキュメントをすばやく確認できます。
なお、各種テキスト分割モードにより、分割表示の方法が異なります。
汎用モード
汎用モードでは、各テキスト分割は独立したブロックとして扱われます。ブロック内の全内容を確認する場合は、右上隅の全画面アイコンをクリックして全画面表示モードに切り替えてください。
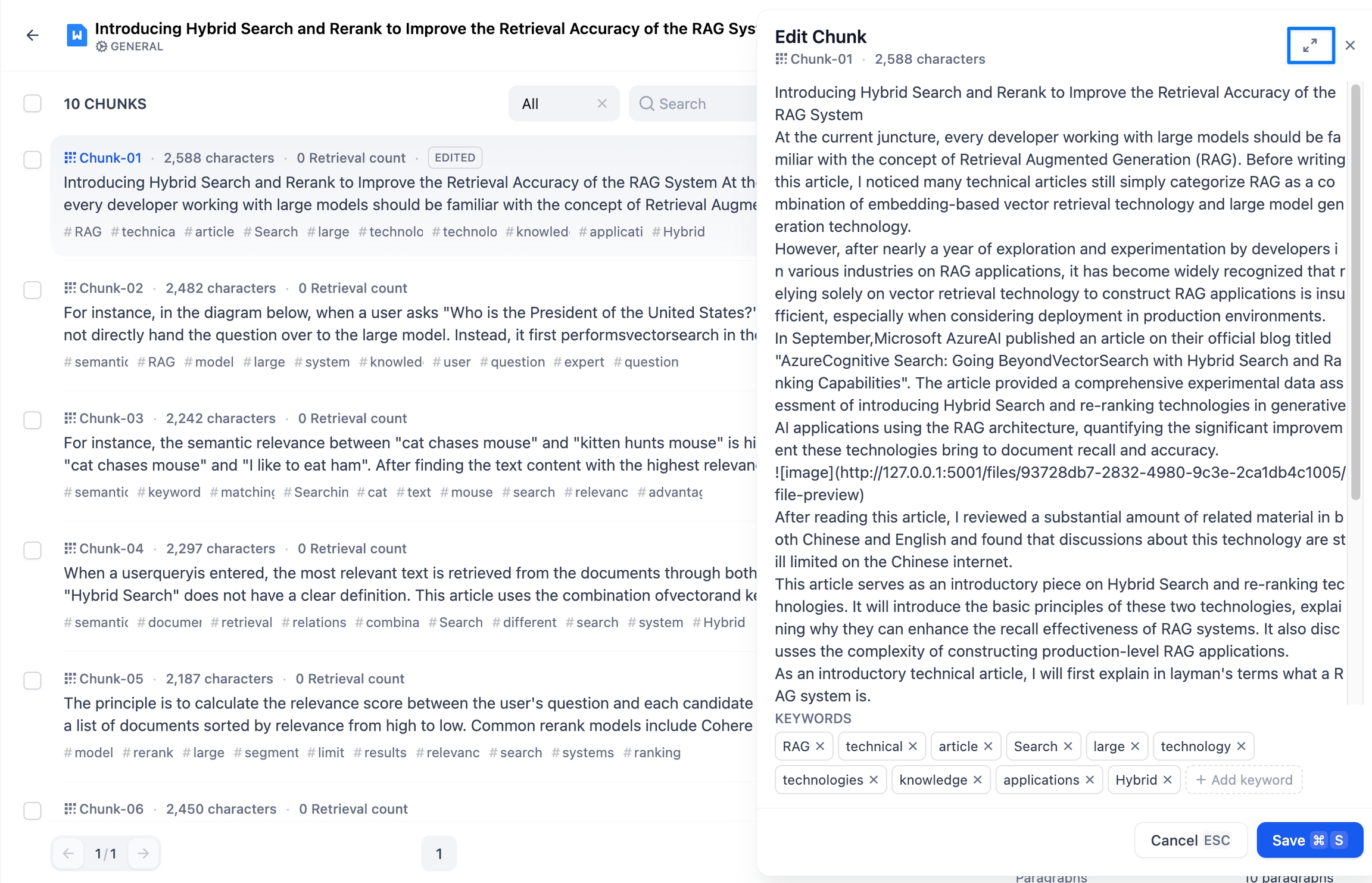
また、上部のドキュメントタイトルをクリックすることで、ナレッジベース内の他ドキュメントへの迅速な切り替えが可能です。


Q&A モード
Q&A モードでは、1つのブロック内に「質問」と「回答」が含まれます。任意のドキュメントタイトルをクリックすると、テキスト分割が表示されます。
分割品質の確認
ドキュメントのテキスト分割は、ナレッジベースを利用した質疑応答システムの精度に大きく影響します。そのため、ナレッジベースとアプリケーションを連携する前に、分割品質を人の目でチェックすることを推奨します。
自動化された文字長、識別子、あるいは NLP の意味解析に基づく分割方法は、大量のテキスト分割作業を大幅に軽減できますが、分割品質はドキュメントの形式や文脈の継続性に依存するため、機械的な処理だけでは十分でない場合があります。人力によるチェックと修正により、機械分割の弱点を補完することが可能です。
分割品質を確認する際、主に以下の点に注意してください。
短すぎるテキスト分割:意味の一部が欠落する可能性があります。

長すぎるテキスト分割:文脈のノイズが生じ、検索精度に影響を与える場合があります。
強制的な意味の切断:最大分割長により、意味が途中で切れてしまう場合があり、検索時に情報が欠落する可能性があります。

テキスト分割の追加
ナレッジベース内のドキュメントは、必要に応じて個別にテキスト分割を追加することが可能です。なお、分割追加の方法は選択している分割モードにより異なります。
テキスト分割の追加は有料機能となります。詳細はこちらをご確認ください。
汎用モード
分割リスト上部の「分割を追加」ボタンをクリックすると、ドキュメント内に任意のテキストブロックを1つまたは複数追加できます。
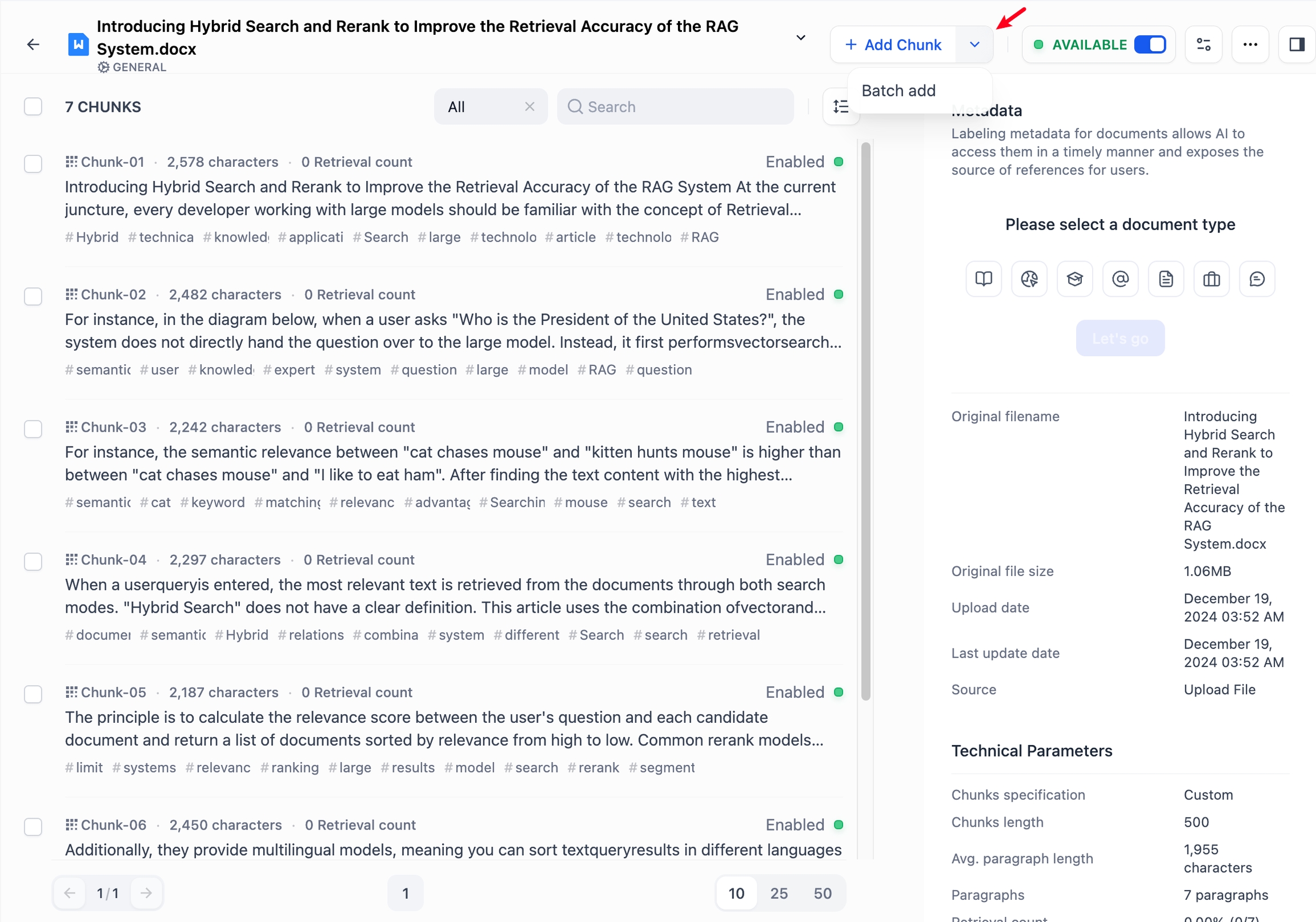
手動でテキスト分割を追加する際は、本文およびキーワードの入力が可能です。入力後、末尾の 「連続追加」 ボタンにチェックを入れると、引き続き新たな分割を追加できます。
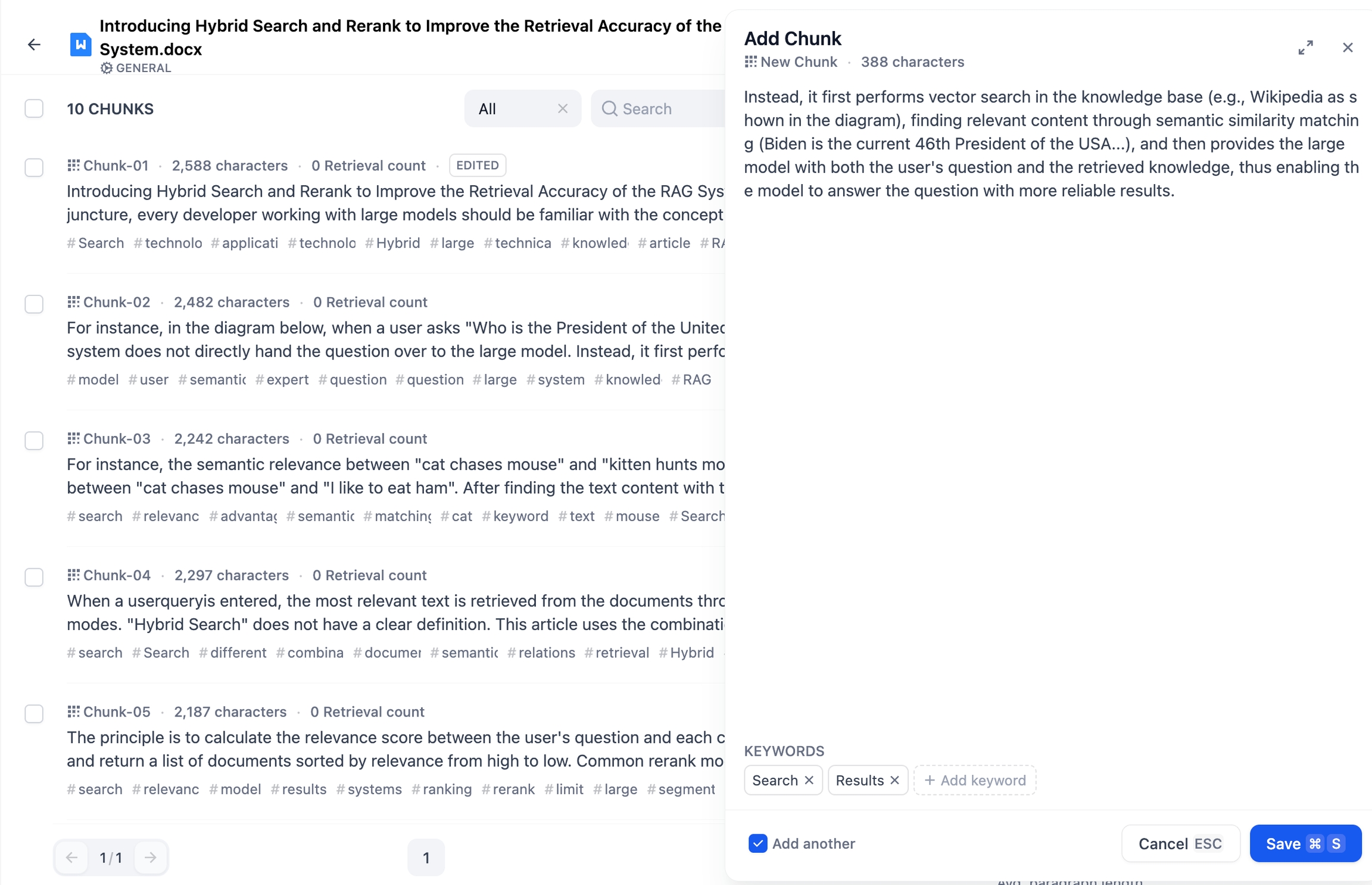
また、一括で分割を追加する場合は、まず CSV 形式の分割アップロード用テンプレートをダウンロードします。Excelなどでテンプレートに沿って内容を編集し、CSVファイルとして保存後、アップロードしてください。
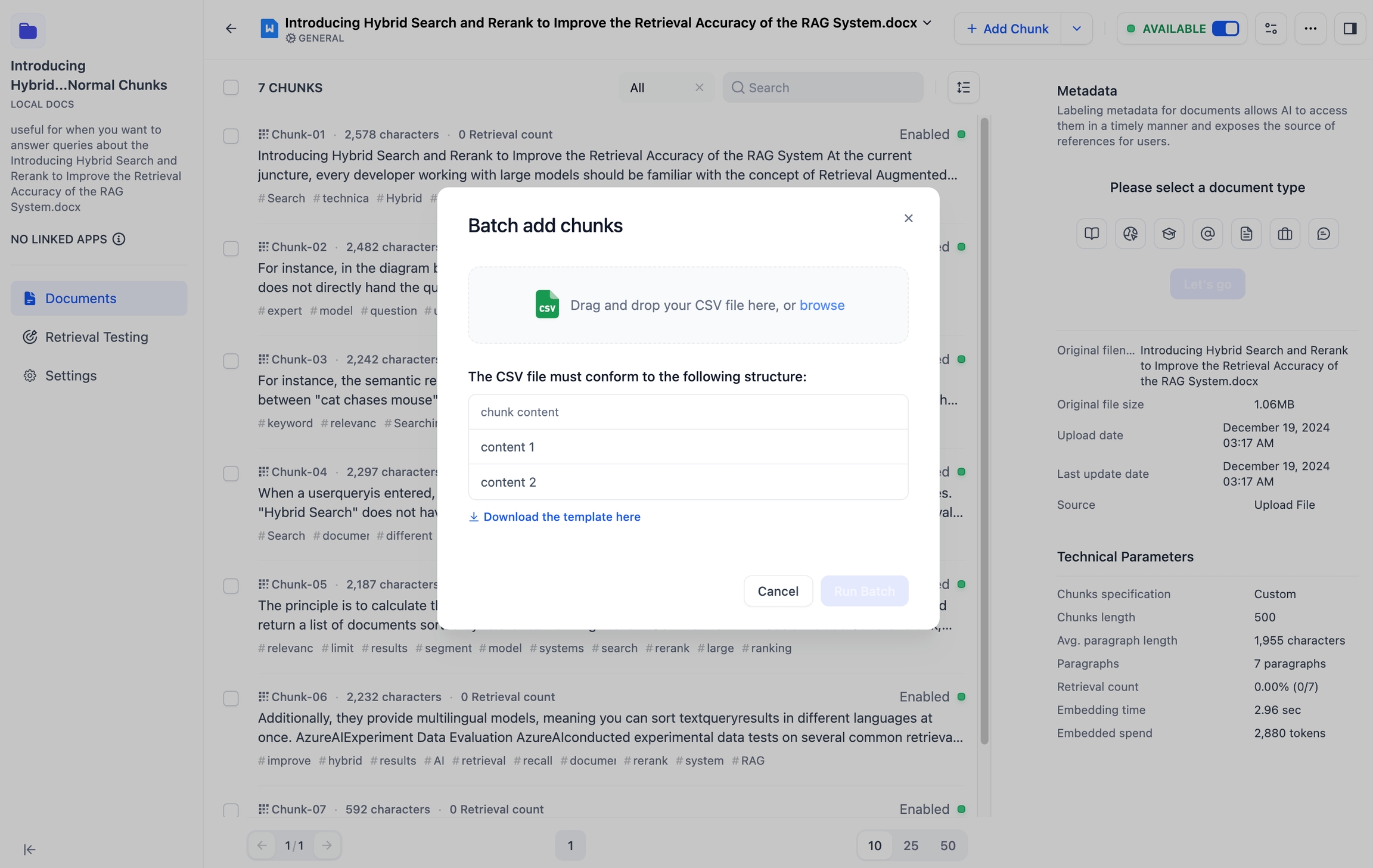
父子モード
分割リスト上部にある「分割を追加」ボタンをクリックすると、文書内に対して、1つまたは複数のカスタムな親分割を一括で追加できます。
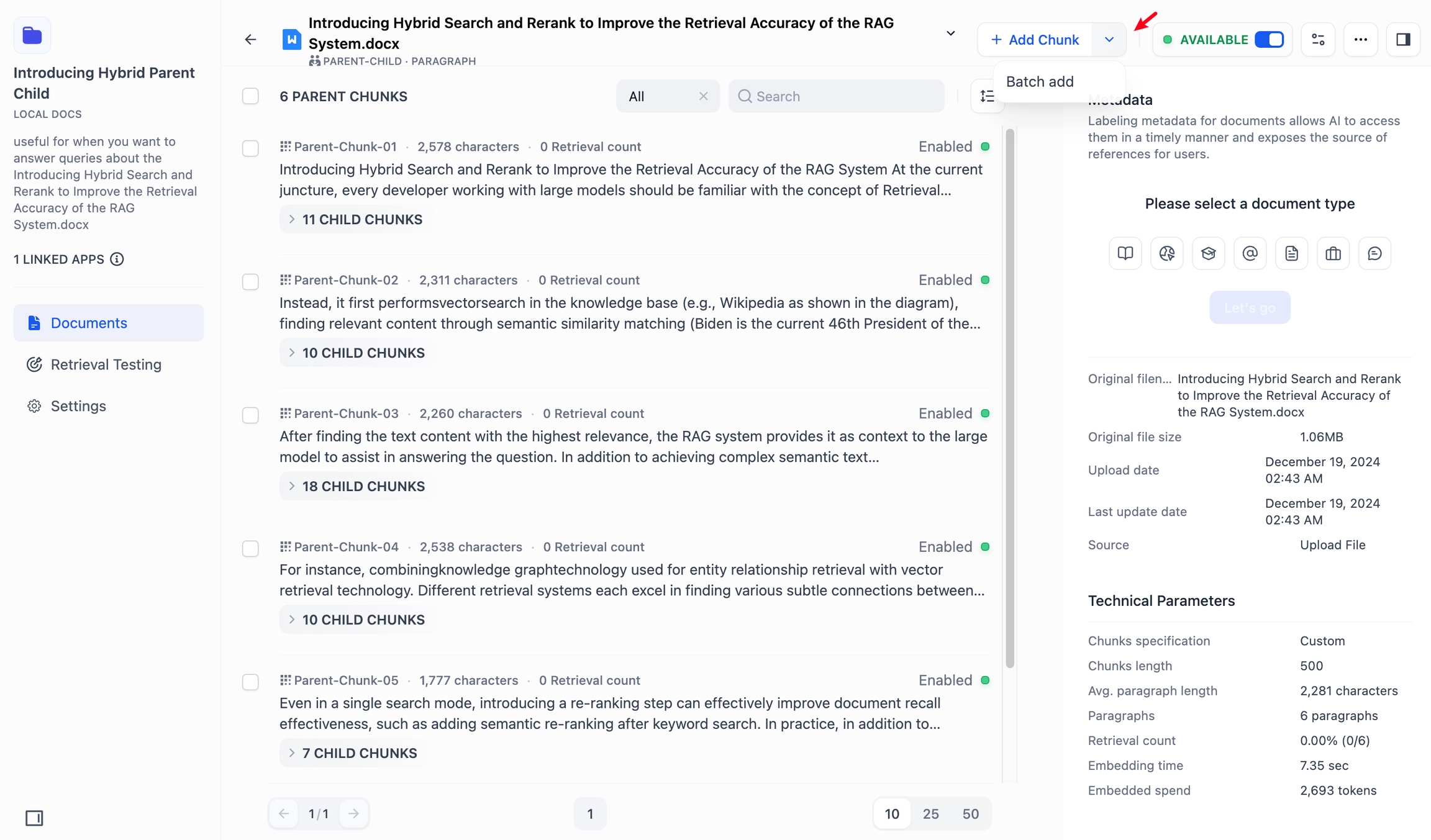
内容を入力後、下部にある 「連続追加」 ボタンにチェックを入れることで、引き続きテキストを追加できます。
また、親分割内において子分割を個別に追加することも可能です。親分割内の子分割右側にある「追加」ボタンをタップすると、子分割を単体で追加できます。
Q&Aモード
分割リスト上部にある「分割を追加」ボタンをクリックすると、文書内に質問と回答のペアによるコンテンツブロックを1つまたは複数追加できます。
テキスト分割の編集
汎用モード
追加された分割の内容は、直接編集・変更が可能です。分割内のテキストやキーワードも自由に変更できます。 また、重複して編集してしまわないよう、編集後のコンテンツブロックには「編集済み」ラベルが表示されます。
父子モード
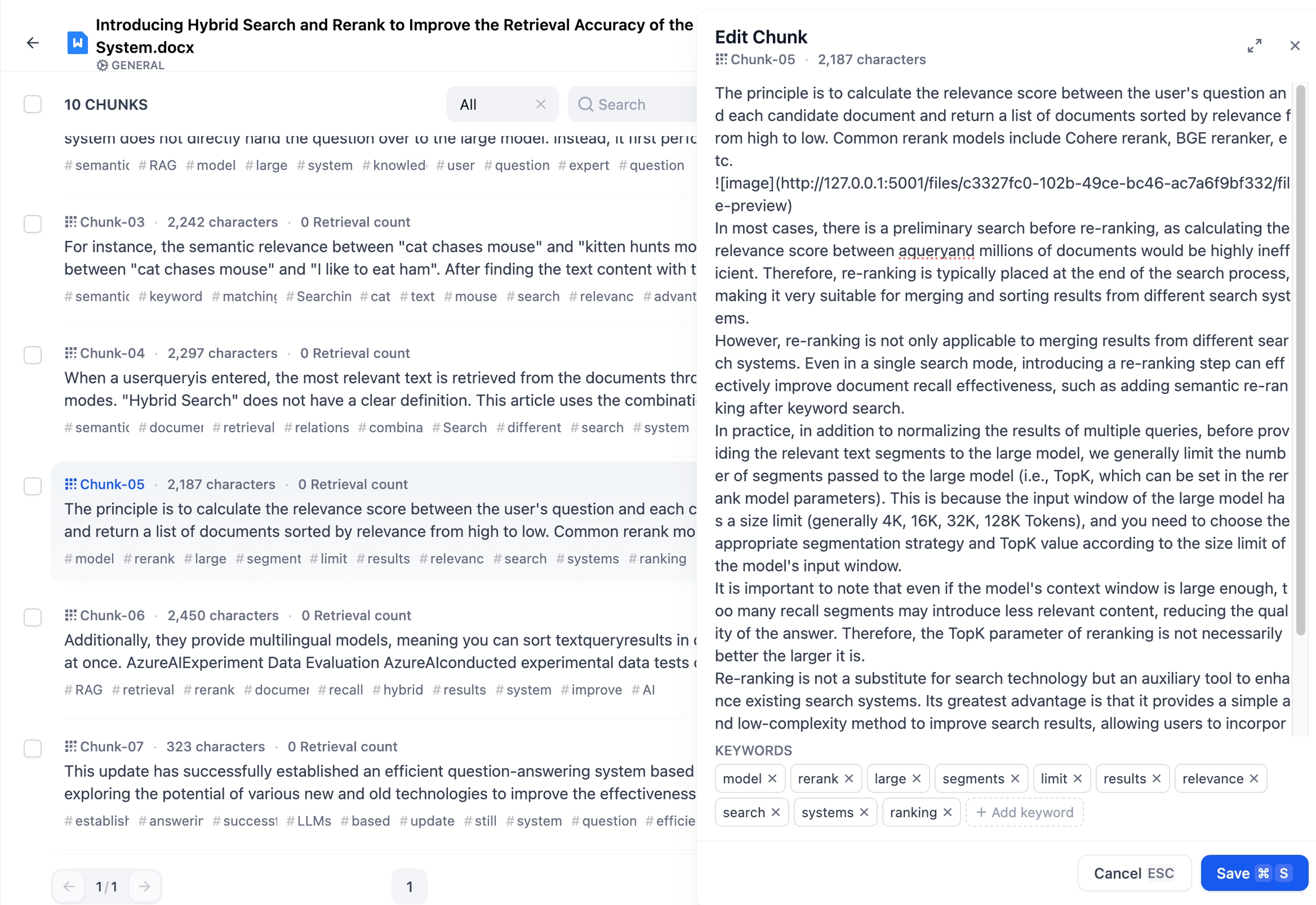
親分割は、内部に含む子分割の内容を保持していますが、双方は独立して編集可能です。つまり、親分割と子分割の内容はそれぞれ別々に変更できます。 下図は、親子分割間の編集フローを示しています。
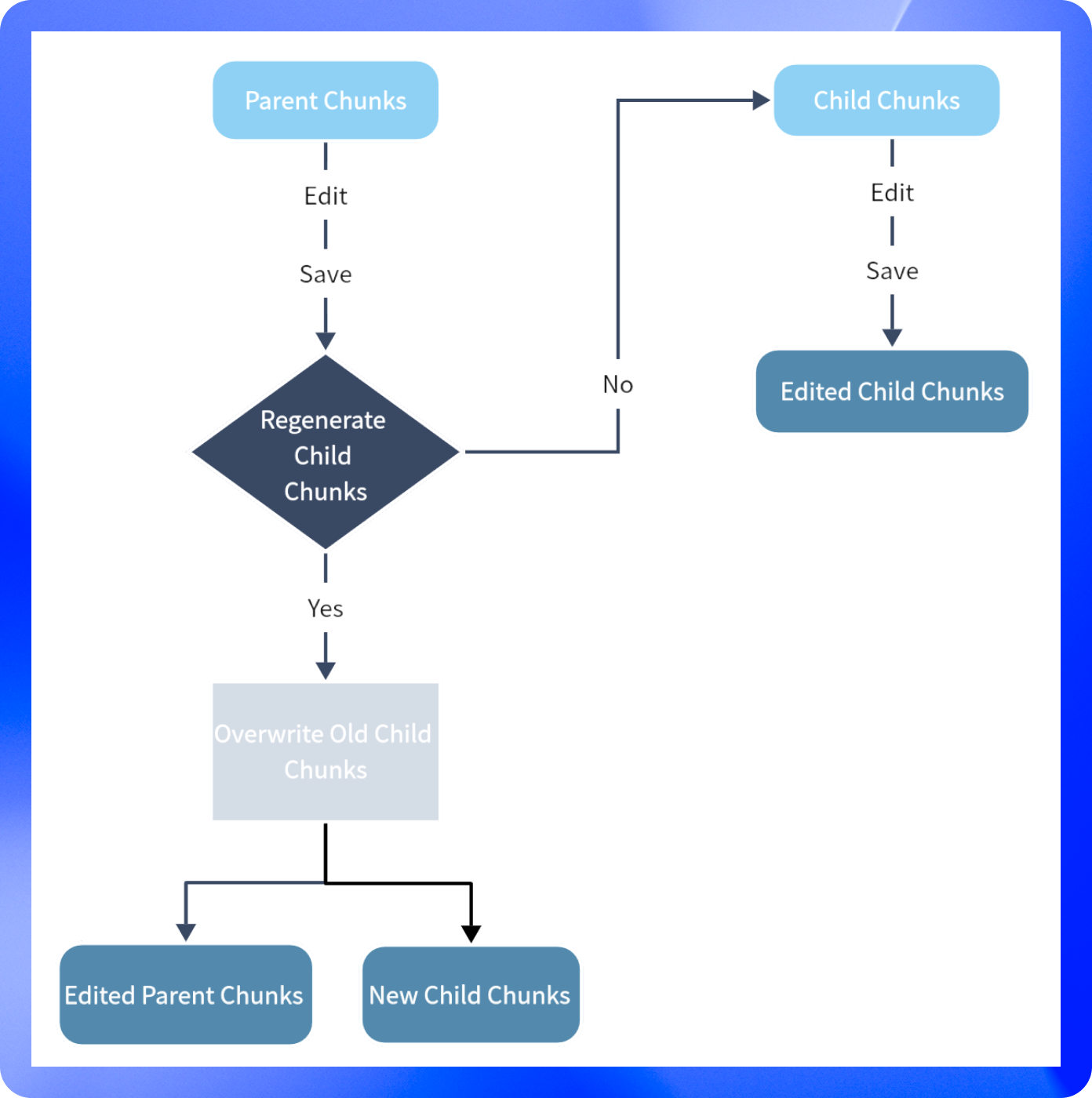
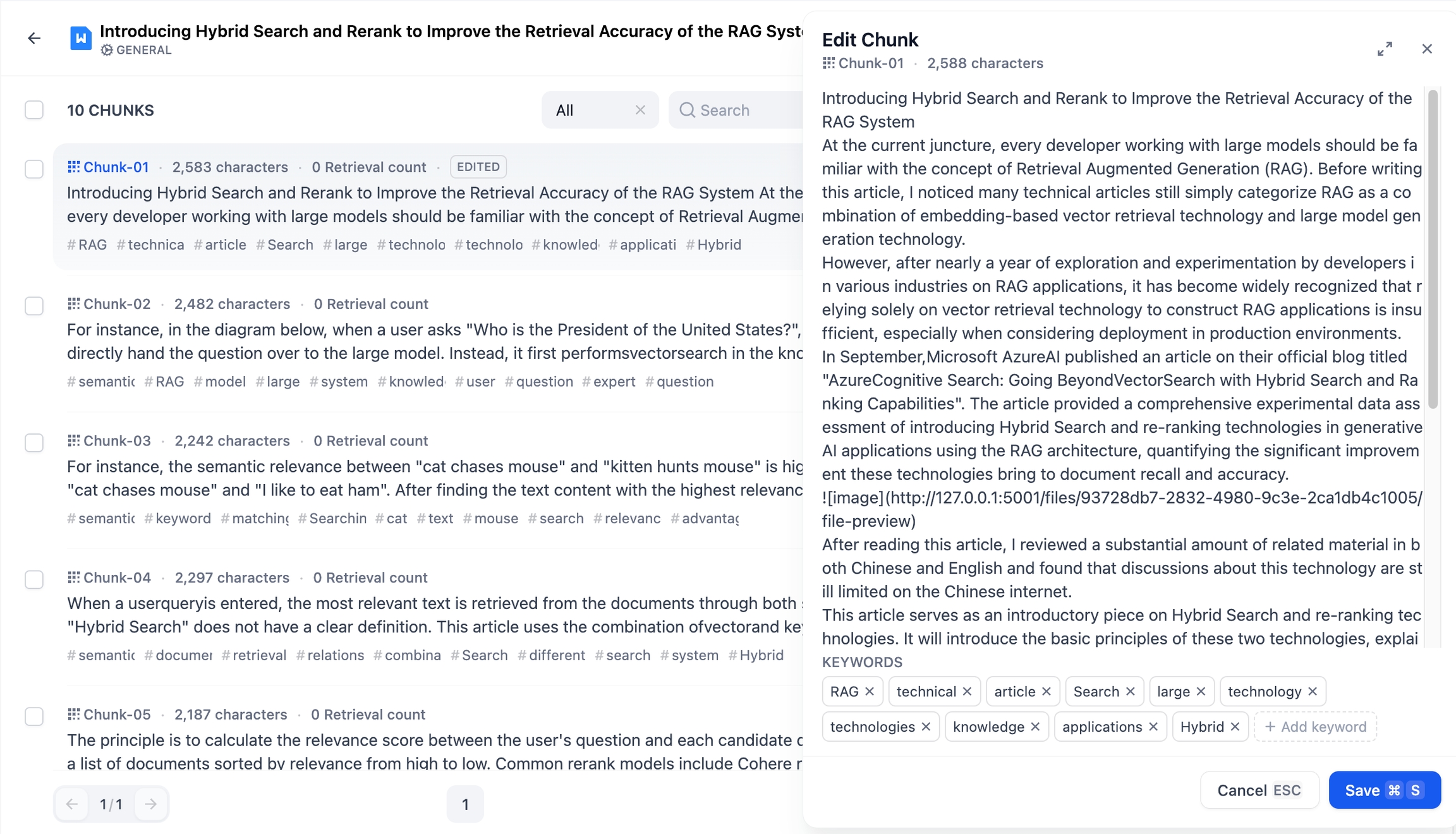
親分割の編集:親分割右側の編集ボタンをクリックし、内容を入力してください。**「保存」**をクリックすると子分割の内容はそのままで、もし子分割の内容も再生成したい場合は 「保存して子分割を再生成」 をクリックしてください。
編集後、重複編集を防止するため、対象のコンテンツブロックには「編集済み」ラベルが表示されます。
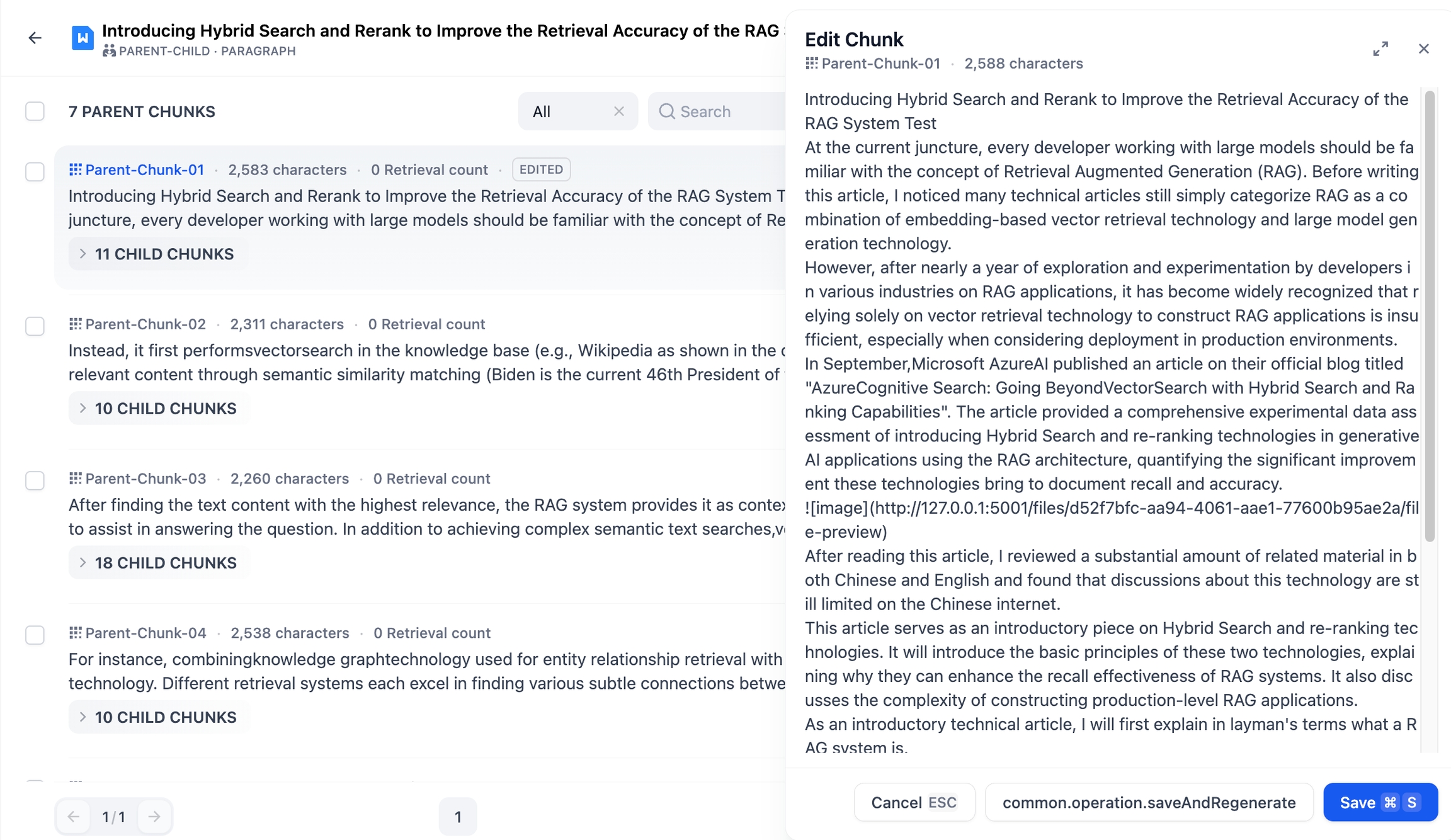
子分割の編集:任意の子分割を選択し編集モードに入った後、変更が完了したら保存してください。なお、子分割の編集内容は親分割には影響しません。編集または新規追加された子分割には、C-NUMBER-EDITEDという濃い青色のラベルが付与されます。
また、子分割は現在の親分割のタグと見なすことも可能です。
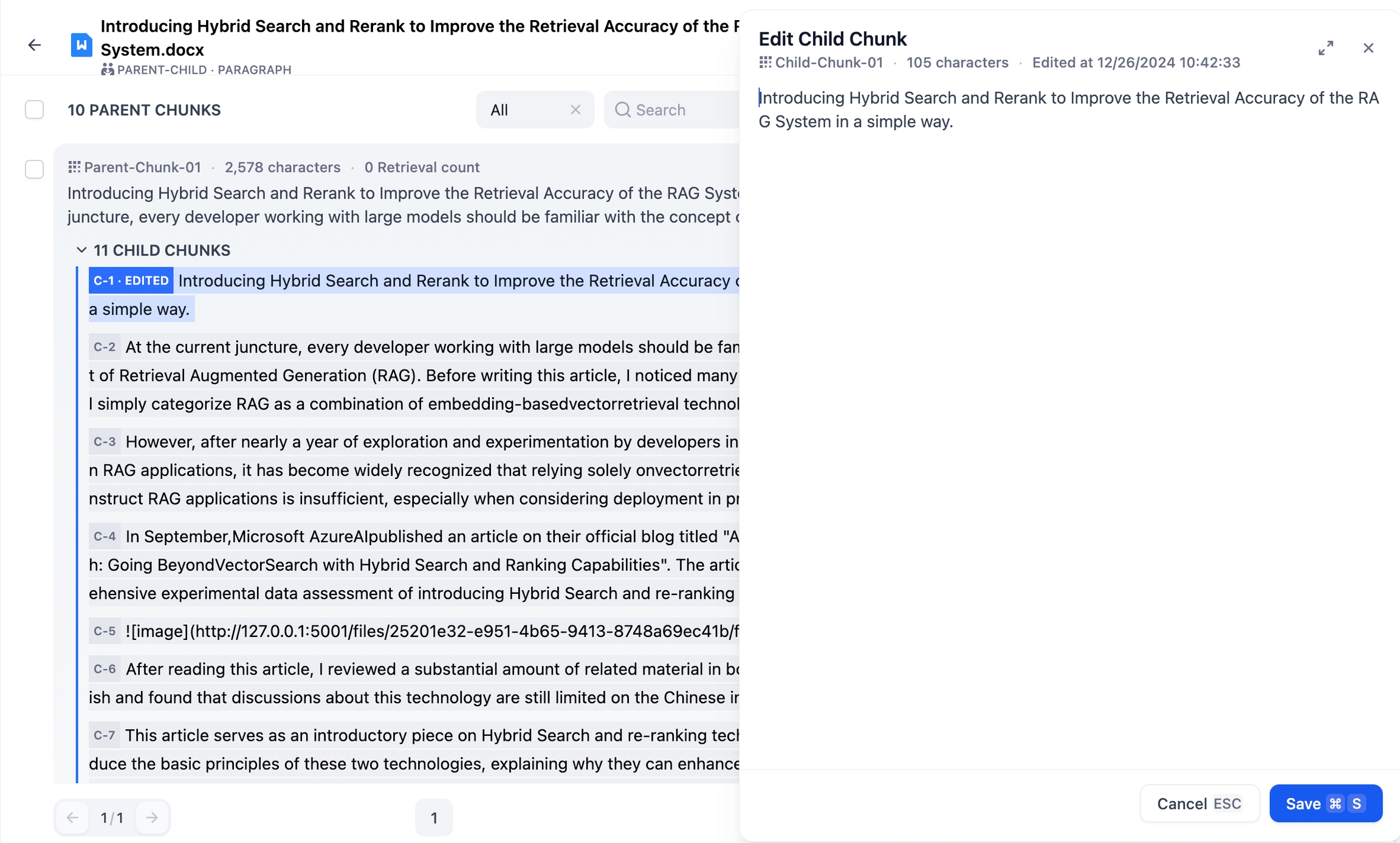
Q&Aモード
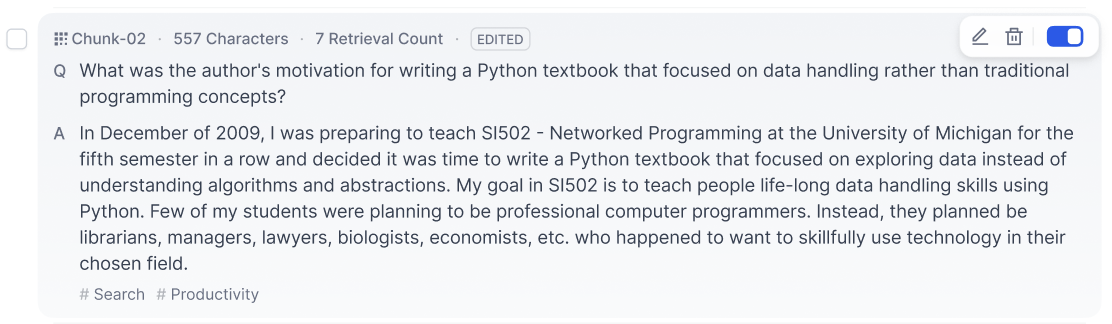
Q&Aモードでは、1つのコンテンツブロック内に質問と回答が含まれています。編集したいテキスト分割をクリックすると、質問と回答それぞれの内容を編集できるほか、現在のコンテンツブロックのキーワードも変更可能です。
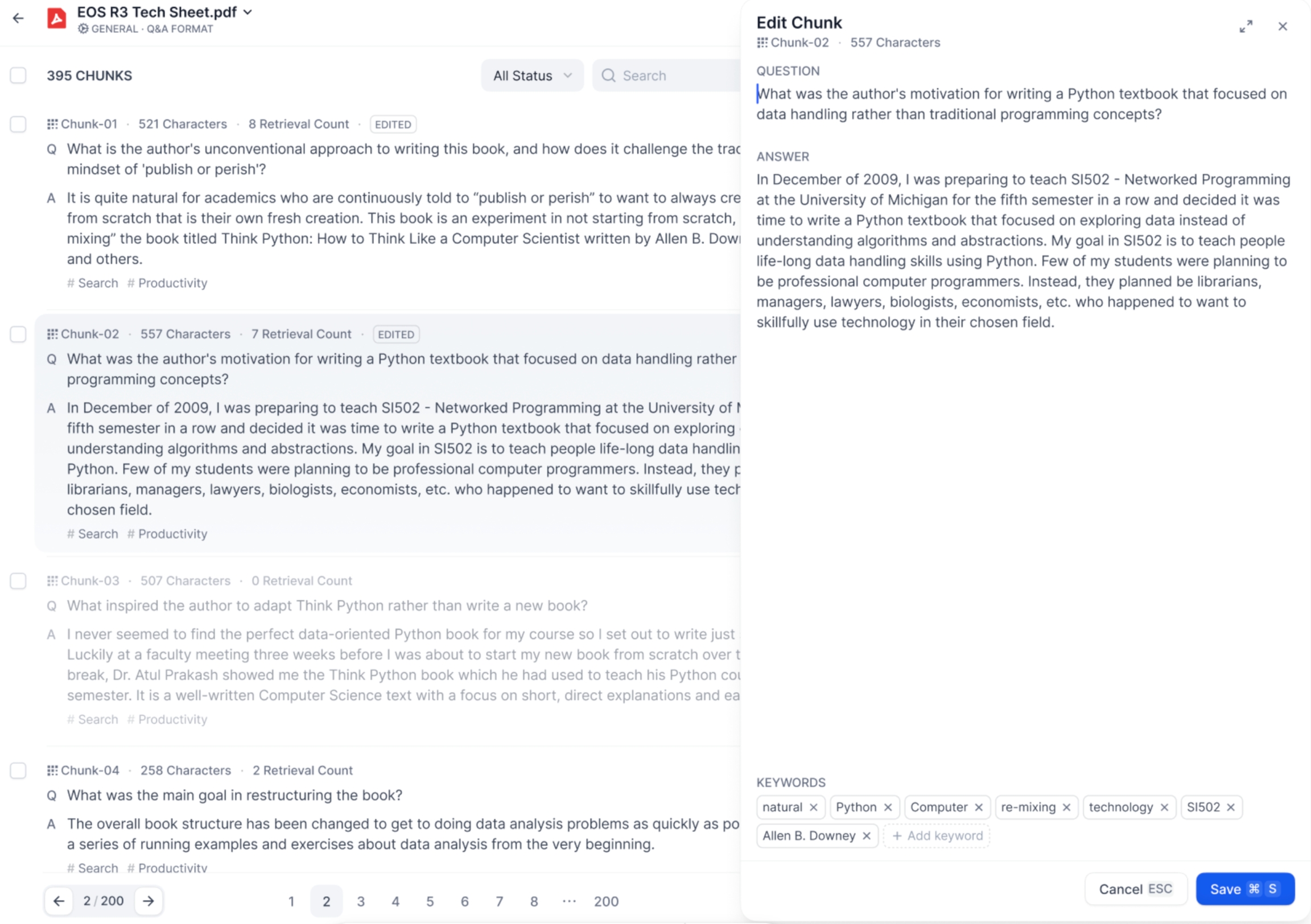
アップロード済み文書のテキスト分割の変更
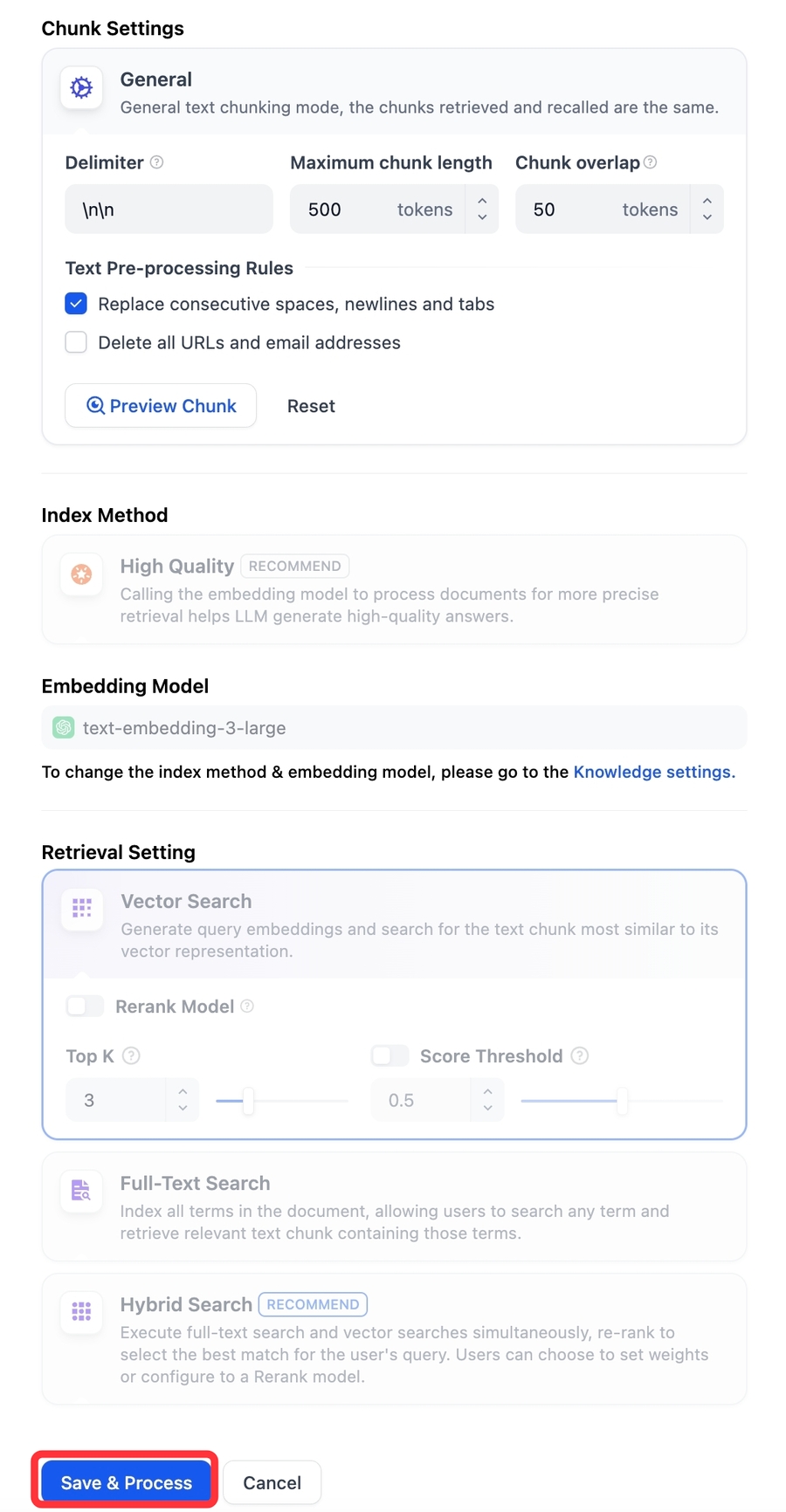
既存のナレッジベースでは、文書の分割設定を再構成することができます。
大きい分割
1つの分割でより多くの文脈(コンテキスト)を保持できるため、複雑なタスクあるいは文脈に依存するタスクに適しています。
分割数が減ることにより、処理時間およびストレージの必要量が削減されます。
小さい分割
より細かい粒度でテキスト内容の正確な抽出や要約が可能です。
モデルのトークン制限を超えるリスクを軽減し、制約が厳しいモデルへの適応性も向上します。
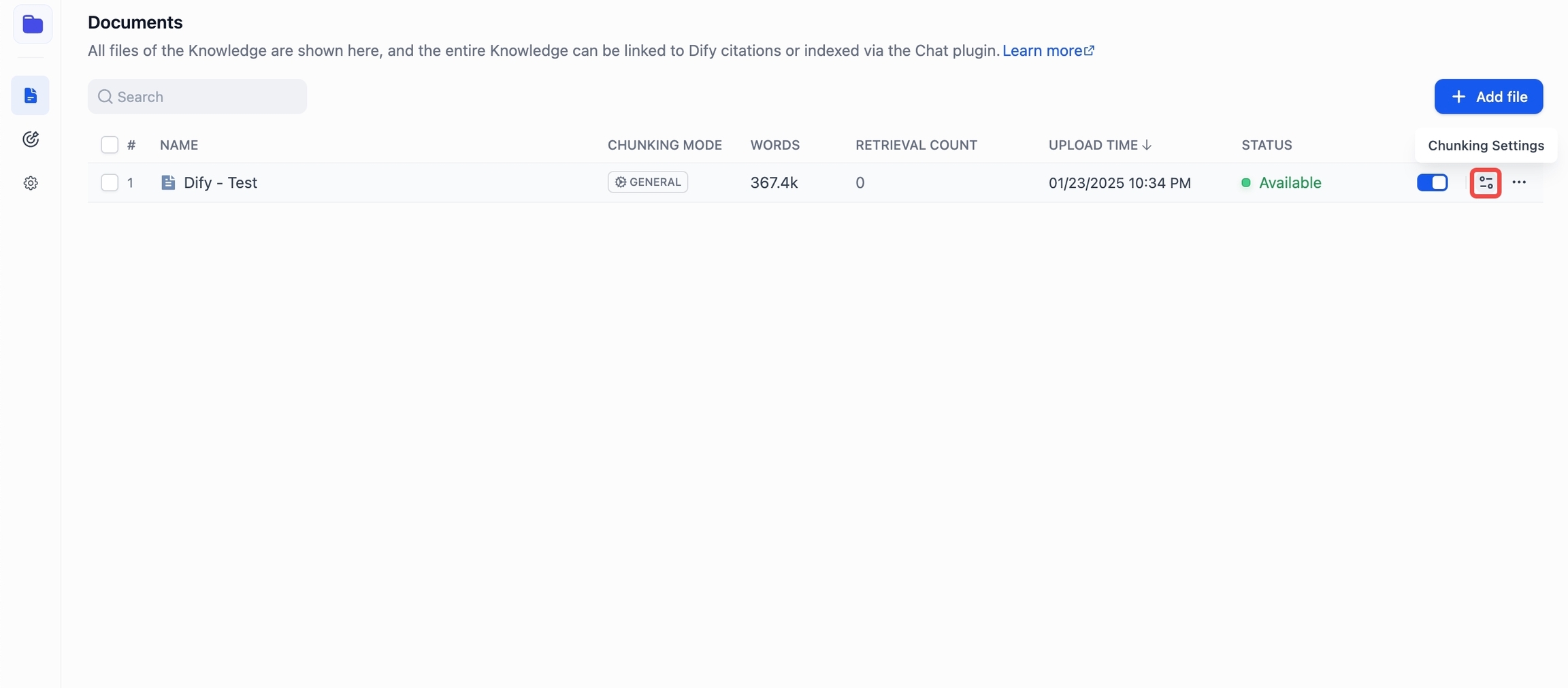
「分割設定」にアクセス後、保存して処理ボタンをクリックすることで、分割設定の変更内容が保存され、現在の文書分割処理が再トリガーされます。 設定保存と埋め込み処理が完了すると、文書の分割リストは自動的に更新され、ページの手動リロードは不要です。
メタデータ管理
メタデータの詳細については、メタデータを参照してください。
Last updated