
ナレッジベース作成
ナレッジベースの作成および文書のアップロード手順は、主に以下のステップから成り立っています:
ナレッジベースを新規作成し、ローカルの文書やオンラインのデータを取り込みます。
文書を分割する際のモードを選び、その効果をプレビューします。
検索機能のためのインデックス設定と検索オプションを構成します。
文書の分割処理が完了するまで待ちます。
アップロードが完了したら、アプリ内でナレッジベースを利用開始します 🎉
各ステップの詳細について説明します:
1. ナレッジベースの新規作成
Difyプラットフォームのトップメニューより 「ナレッジベース」→「新規作成」 を選択します。文書は、ローカルファイルのアップロードまたはオンラインデータの取り込みによってナレッジベースに追加できます。
ローカルファイルのアップロード:ファイルをドラッグ&ドロップまたは選択してアップロードします。一度に多数のファイルをアップロードすることが可能ですが、その上限はサブスクリプションプランに依存します。
ローカルファイルのアップロードには以下の制約があります:
一度にアップロードできる最大サイズは15MBです;
使用しているSaaSサブスクリプションプランによって、一括アップロード可能なファイル数、文書の総アップロード数、ベクトルストレージの利用可能容量が制限されます。
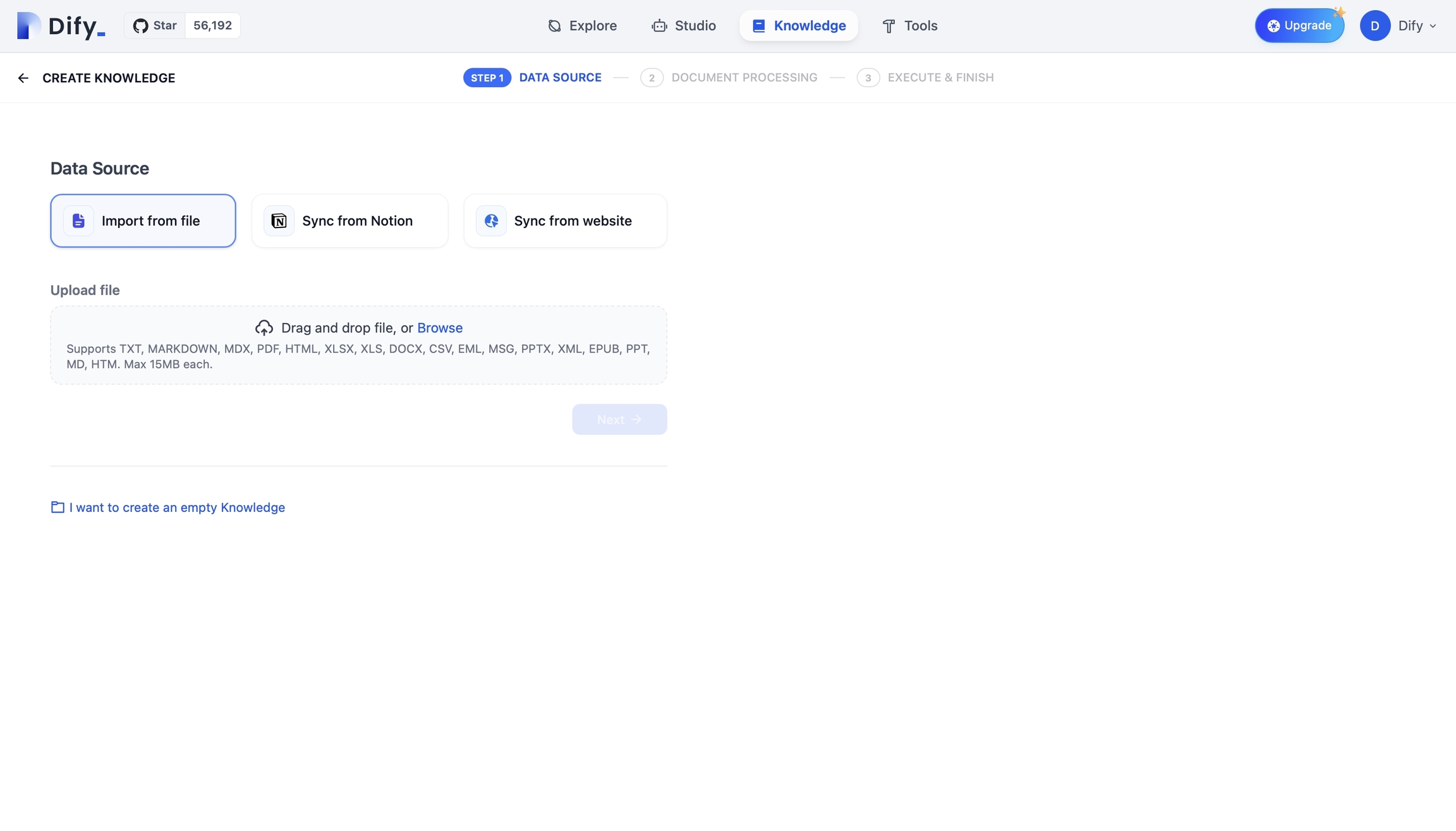
ナレッジベースの作成 オンラインデータの取り込み:ナレッジベース作成時にオンラインデータの取り込みが可能で、詳細はオンラインデータ取り込みのガイドを参照してください。オンラインデータソースを利用するナレッジベースには、後からローカルの文書を追加したり、ローカルファイルタイプのナレッジベースへ変更したりすることはできません。これは、複数のデータソースが混在すると管理が複雑になるためです。
文書がまだ準備できていない場合でも、空のナレッジベースを先に作成し、後ほどローカル文書をアップロードしたり、オンラインデータを取り込んだりすることができます。
2. コンテンツ分割の指定方法
コンテンツをナレッジベースにアップロードした後の次のステップは、コンテンツの分割とデータのクレンジングです。このステップでは、コンテンツの前処理とデータの構造化が行われ、長いテキストは複数のセクションに分けられます。 LLMはユーザーからの質問を受け取った際、ナレッジベース内のセクションをどれだけ正確に検索し取り出せるかで、その質問に対する正確な回答が可能かどうかが決まります。詳細については、コンテンツ分割の指定方法をご参照ください。
以下の2つの分割モードがあります:
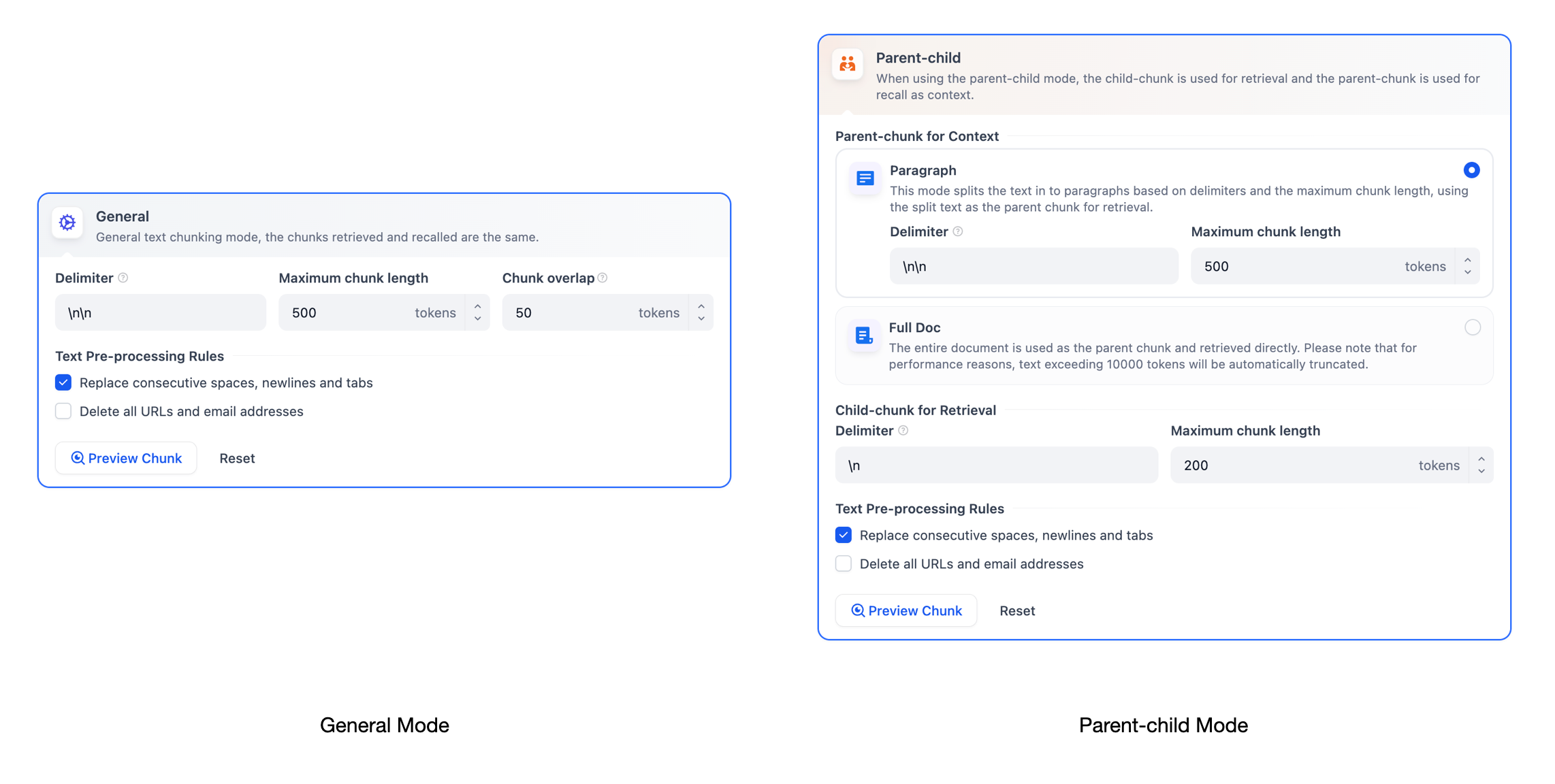
汎用分割モード
このモードでは、システムがユーザーが定義したルールに従ってコンテンツを独立したセクションに分けます。質問が入力されると、システムはその質問のキーワードを自動で分析し、これらのキーワードとナレッジベース内のセクションとの関連度を計算します。そして、関連度に基づいてセクションをランキングし、最も関連性の高いセクションを選びLLMへ送り、処理して回答を得ます。
注意:以前の 「自動分割とクリーニング」モード は 汎用分割モード に自動的に更新されました。何も変更する必要はなく、デフォルト設定をそのまま使用し続けることができます。
親子分割モード(階層分割モード)
二層の構造を採用し、検索精度とコンテキスト情報のバランスを取ります。このモードでは、親セクション(Parent-chunk)がより大きなテキスト単位(例えば段落)を包含し、豊富なコンテキスト情報を提供します。子セクション(Child-chunk)はより小さなテキスト単位(例えば文)で、精確な検索に利用されます。システムは最初に子セクションを通じて精確な検索を行い関連性を確保した後、対応する親セクションを取得しコンテキスト情報を補完し、レスポンスを生成する際に正確さを保ちながら完全な背景情報を提供します。セクションの分割方法は、区切り文字と最大長さの設定を通してカスタマイズできます。
ナレッジベースを初めて作成する際は、親子分割モードを選択し、デフォルトのオプションを使用してナレッジベースの作成を行うことを推奨します。コンテンツセクションをカスタマイズしたい場合は、分割ルールを参照し、正規表現の文法に従って設定してください。
注意:分割モードを選択し、ナレッジベースの作成を完了した後は、後からモードを変更することはできません。ナレッジベースにドキュメントを新たに追加する場合も、選択したコンテンツ分割戦略に従います。
インデックス設定方法
コンテンツを構造化する前処理(分割とクリーニング)を行った後、構造化されたコンテンツに対してどのように検索を行うかの設定が必要です。検索エンジンが効率的なインデックスアルゴリズムを用いて、ユーザーの問い合わせに最も関連性の高い検索結果を提供できるように、インデックスの設定方法が重要です。これは、LLMがナレッジベースから情報を検索する効率と回答の精度に直接影響します。
以下に、三つのインデックス設定方法を紹介します。詳細はインデックス設定方法をご覧ください。
高品質
エンベッディングモデル(Embeddingモデル)を利用して、分割されたテキストブロックを数値ベクトルに変換し、大量のテキスト情報をより効率的に圧縮・保管します。これにより、ユーザーの問い合わせとテキストとのマッチングがより精密に行われます。
経済的
各テキストブロックごとに10個のキーワードを用いて検索を行います。精度は落ちますが、追加のコストはかかりません。
Q&Aモード(コミュニティ版のみ対応)
ナレッジベースへの文書アップロード時に、システムがテキストを分割して要約し、各ブロックごとにQ&Aのペアを生成します。FAQ形式の文書に適しています。
高品質なインデックス設定方法の利用を推奨します。

4. 検索方法の選定
ユーザーからの問い合わせを受けた後、ナレッジベースは関連する情報を既存のドキュメントから見つけ出すために検索方法を用いる。ビジネスの要求やデータの特徴に合わせて、検索方法を柔軟に組み合わせたり変更したりすることで、より効果的かつ正確な検索結果を提供できる。
異なるインデックス作成方法によって、様々な検索オプションが提供される。詳細は検索方法の選定セクションを参照。
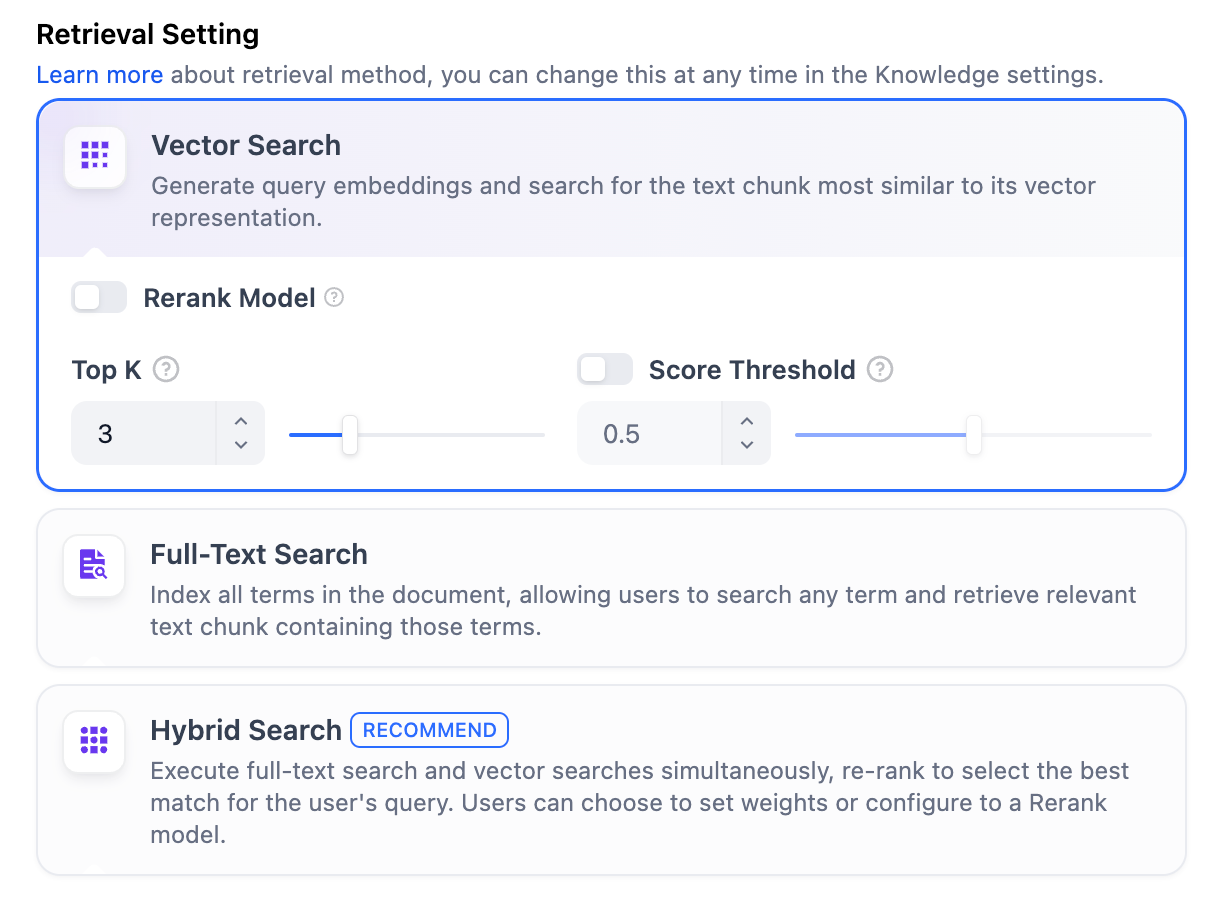
高品質インデックス
ベクトル検索
ユーザーの質問をベクトル化し、クエリテキストの数値ベクトルを作成。このクエリベクトルとナレッジベース内のテキストベクトルとの距離を比較し、最も近い内容を探索する。
全文検索
キーワードによる検索で、ドキュメント内の全単語を索引付ける。ユーザーが質問を提出すると、そのキーワードでナレッジベース内の適切なテキスト部分を検索し、一致する内容を返す。これは検索エンジンにおける一般的な全文検索と似ている。
ハイブリッド検索(推奨)
全文検索とベクトル検索を同時に行い、リランクモデルを用いて両方の検索結果から最も適切な回答を選び出す。
経済的安いインデックス
インバーテッド検索
インバーテッド検索は、ドキュメント内のキーワードを迅速に検索するための索引構造で、オンライン検索エンジンで広く使用されている。
選んだ検索方式に基づき、リコールテスト/引用帰属セクションを参照し、キーワードとコンテンツの一致度をテストできる。
5. アップロード完了
上述した設定を終えて、「保存して処理」ボタンをクリックすることで、ナレッジベースの作成が完了する。アプリ内でナレッジベースを統合する方法については、ナレッジベースの統合セクションを参照。ナレッジベースの更新や管理が必要な場合は、ナレッジベースの管理と文書のメンテナンスセクションをご覧ください。
参考文献
ETL
RAGのプロダクションレベルのアプリケーションでは、データ召喚の効果を向上させるために、複数のデータソースを前処理およびクリーニングする必要があります。これをETL(抽出、変換、ロード)と呼びます。非構造化/半構造化データの前処理能力を強化するために、Difyは以下のオプションのETLソリューションをサポートしています:Dify ETL とUnstructured ETL。Unstructuredは、データを抽出してクリーンなデータに変換し、後続のステップに使用できるようにします。Difyの各バージョンでのETLソリューションの選択:
SaaS版では選択不可、デフォルトでUnstructured ETLを使用。
コミュニティ版では選択可能、デフォルトでDify ETLを使用、環境変数を介してUnstructured ETLを有効にできます。
ファイル解析のサポート形式の違い:
txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv
txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub
異なるETLソリューションではファイル抽出の効果にも違いがあります。Unstructured ETLのデータ処理方法について詳細を知りたい場合は、公式ドキュメントを参照してください。
埋め込み (Embedding)
**埋め込み(Embedding)**は、単語や文章、あるいはドキュメント全体のような離散変数を、連続ベクトル表現に変換する技術を指します。この技術を用いることで、単語やフレーズ、画像などの高次元データを、より小さな次元空間にマッピングし、データを簡潔かつ効率的に表現できます。この方法は、データの次元を減らすだけでなく、重要な意味の情報も保持し、コンテンツの検索を効率化します。
埋め込みモデルは、テキストデータを数値ベクトル化することに特化した言語モデルの一種で、テキストを密度の高い数値ベクトルに変換し、その意味内容を効果的に表現することに長けています。
メタデータ
メタデータ機能を使用してナレッジベースを管理する場合は、メタデータを参照してください。
Last updated