
接入 GPUStack 进行本地模型部署
部署 GPUStack
Linux 或 MacOS
curl -sfL https://get.gpustack.ai | sh -s -Windows
Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content部署模型
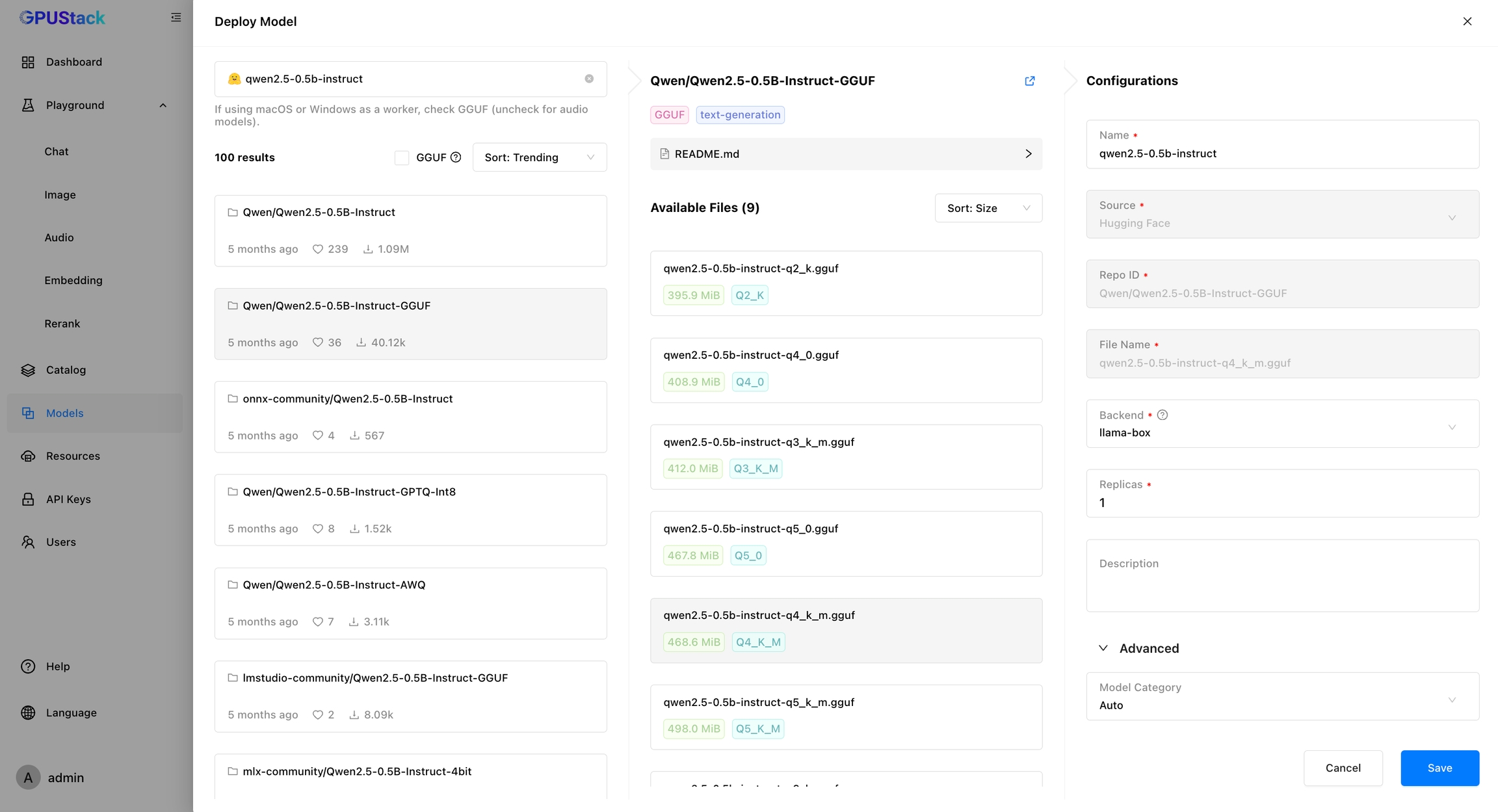
创建 API 密钥
将 GPUStack 集成到 Dify
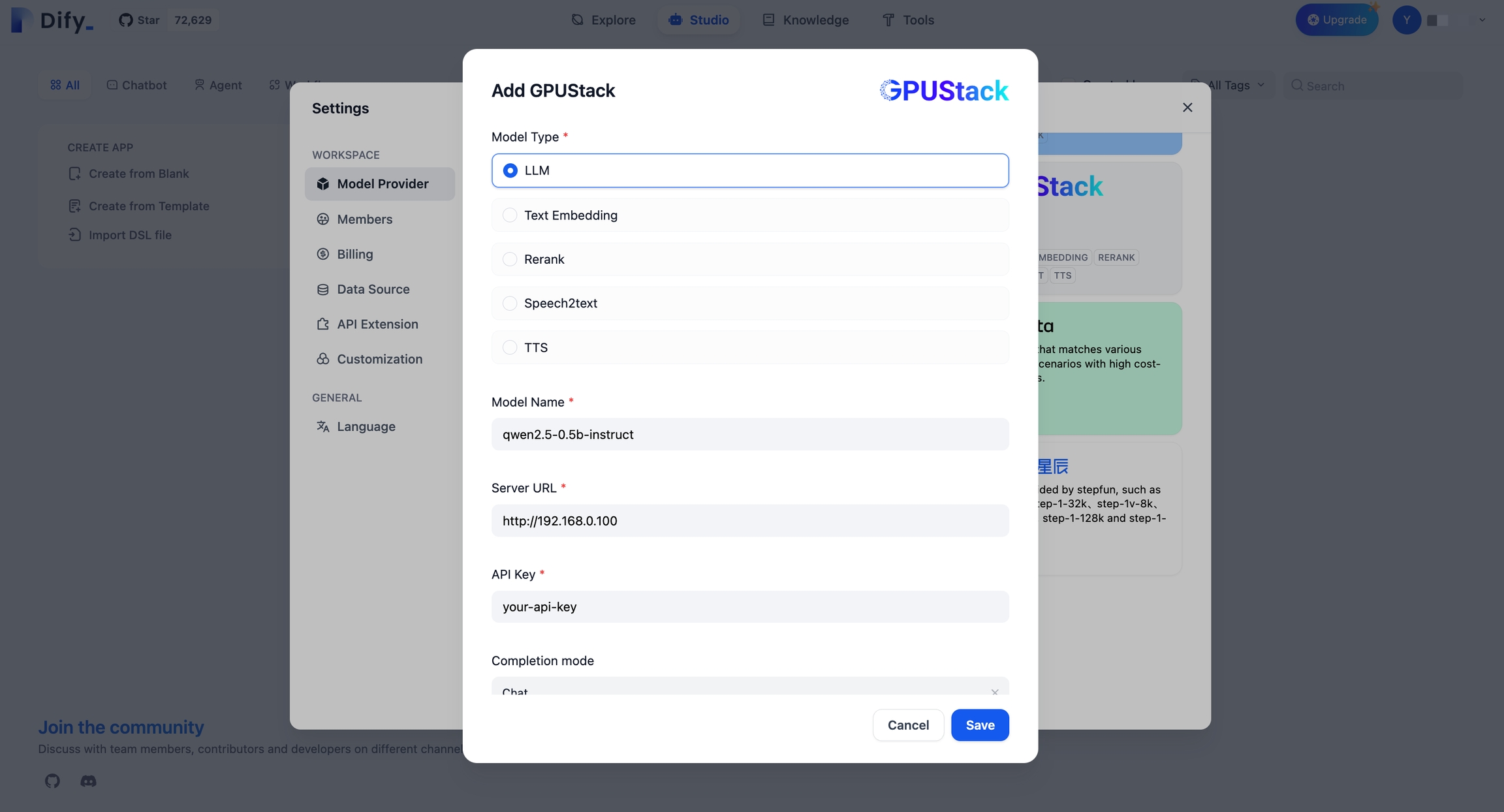
Last updated