
Create Knowledge
Steps to upload documents to create a knowledge base:
Create a knowledge base and import either local document file or online data.
Choose a chunking mode and preview the spliting results. This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.
Configure the indexing method and retrieval setting. Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks.
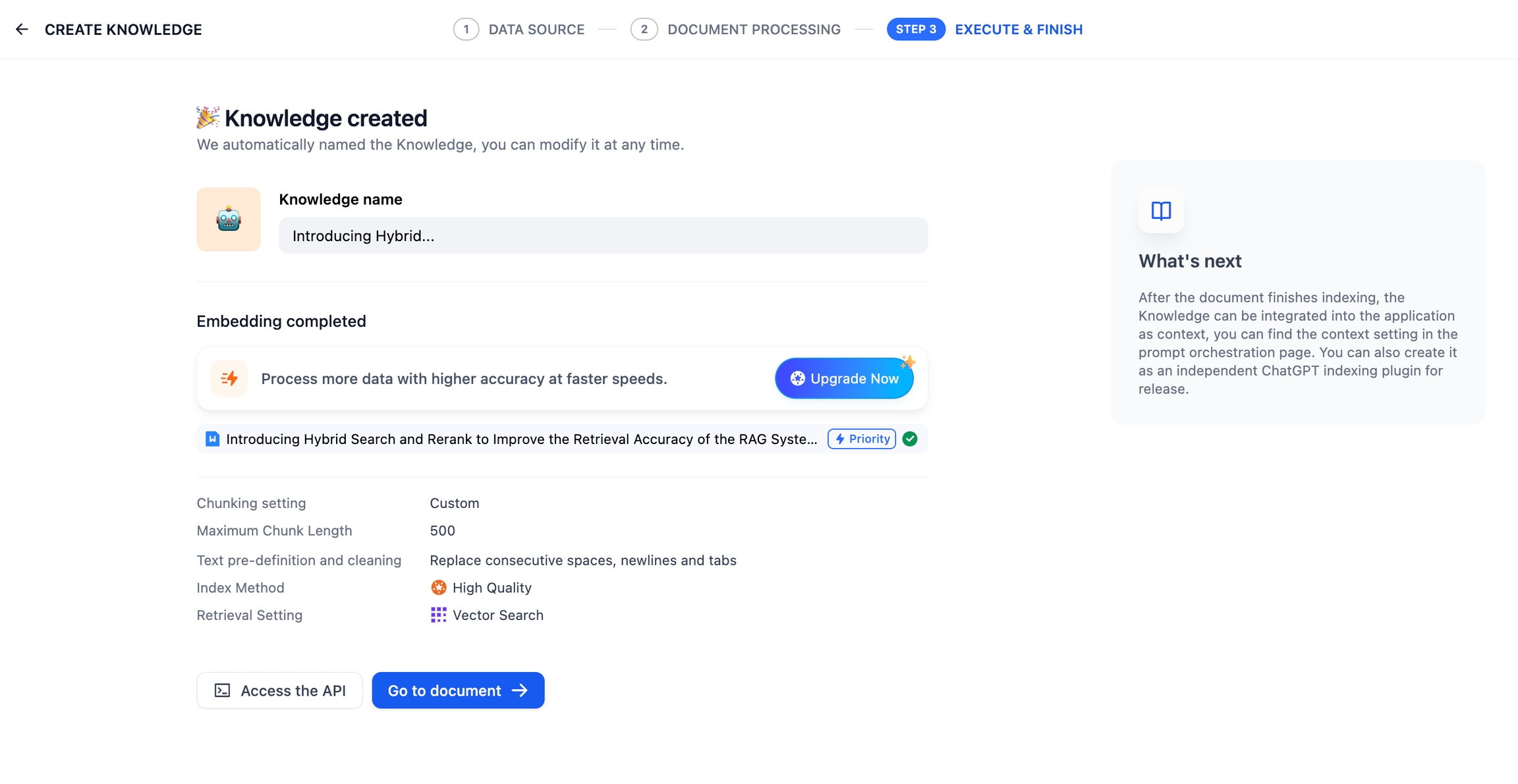
Wait for the chunk embeddings to complete.
Once finished, link the knowledge base to your application and start using it. You can then integrate it into your application to build an LLM that are capable of Q&A based on knowledge-bases. If you want to modify and manage the knowledge base further, take refer to Knowledge Base and Document Maintenance.
Reference
ETL
In production-level applications of RAG, to achieve better data retrieval, multi-source data needs to be preprocessed and cleaned, i.e., ETL (extract, transform, load). To enhance the preprocessing capabilities of unstructured/semi-structured data, Dify supports optional ETL solutions: Dify ETL and Unstructured ETL.
Unstructured can efficiently extract and transform your data into clean data for subsequent steps.
ETL solution choices in different versions of Dify:
The SaaS version defaults to using Unstructured ETL and cannot be changed;
The community version defaults to using Dify ETL but can enable Unstructured ETL through environment variables;
Differences in supported file formats for parsing:
txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv
txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv, eml, msg, pptx, ppt, xml, epub
Different ETL solutions may have differences in file extraction effects. For more information on Unstructured ETL’s data processing methods, please refer to the official documentation.
Embedding
Embedding transforms discrete variables (words, sentences, documents) into continuous vector representations, mapping high-dimensional data to lower-dimensional spaces. This technique preserves crucial semantic information while reducing dimensionality, enhancing content retrieval efficiency.
Embedding models, specialized large language models, excel at converting text into dense numerical vectors, effectively capturing semantic nuances for improved data processing and analysis.
Metadata
For managing the knowledge base with metadata, see Metadata.
Last updated