
变量赋值
定义
变量赋值节点用于向可写入变量进行变量赋值,已支持以下可写入变量:
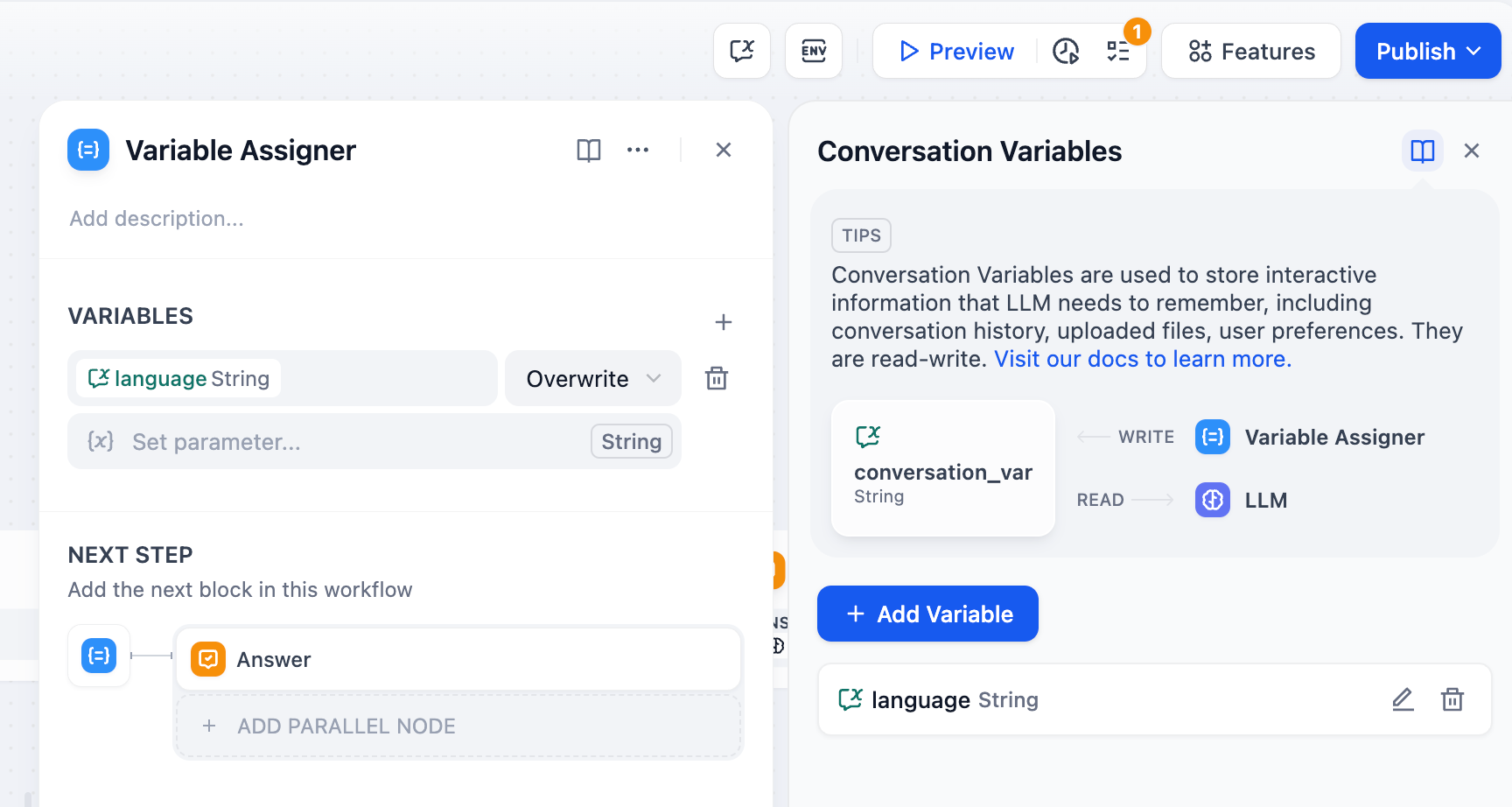
用法:通过变量赋值节点,你可以将工作流内的变量赋值到会话变量中用于临时存储,并可以在后续对话中持续引用。
场景示例
你可以将对话过程中的上下文、上传至对话框的文件、用户所输入的偏好信息等变量,通过变量赋值节点写入至会话变量内,用作后续对话的参考信息。
场景 1
自动判断提取并存储对话中的信息,在会话内通过会话变量数组记录用户输入的重要信息,并在后续对话中让 LLM 基于会话变量中存储的历史信息进行个性化回复。
示例:开始对话后,LLM 会自动判断用户输入是否包含需要记住的事实、偏好或历史记录。如果有,LLM 会先提取并存储这些信息,然后再用这些信息作为上下文来回答。如果没有新的信息需要保存,LLM 会直接使用自身的相关记忆知识来回答问题。

配置流程:
设置会话变量:首先设置一个会话变量数组
memories,类型为 array[object],用于存储用户的事实、偏好和历史记录。判断和提取记忆:
添加一个条件判断节点,使用 LLM 来判断用户输入是否包含需要记住的新信息。
如果有新信息,走上分支,使用 LLM 节点提取这些信息。
如果没有新信息,走下分支,直接使用现有记忆回答。
变量赋值/写入:
在上分支中,使用变量赋值节点,将提取出的新信息追加(append)到
memories数组中。使用转义功能将 LLM 输出的文本字符串转换为适合存储在 array[object] 中的格式。
变量读取和使用:
在后续的 LLM 节点中,将
memories数组中的内容转换为字符串,并插入到 LLM 的提示词 Prompts 中作为上下文。LLM 使用这些历史信息来生成个性化回复。
图中的 code 节点代码如下:
将字符串转义为 object
将 object 转义为字符串
场景 2
记录用户的初始偏好信息,在会话内记住用户输入的语言偏好,在后续对话中持续使用该语言类型进行回复。
示例:用户在对话开始前,在 language 输入框内指定了 “中文”,该语言将会被写入会话变量,LLM 在后续进行答复时会参考会话变量中的信息,在后续对话中持续使用“中文”进行回复。

配置流程:
设置会话变量:首先设置一个会话变量 language,在会话流程开始时添加一个条件判断节点,用来判断 language 变量的值是否为空。
变量写入/赋值:首轮对话开始时,若 language 变量值为空,则使用 LLM 节点来提取用户输入的语言,再通过变量赋值节点将该语言类型写入到会话变量 language 中。
变量读取:在后续对话轮次中 language 变量已存储用户语言偏好。在后续对话中,LLM 节点通过引用 language 变量,使用用户的偏好语言类型进行回复。
场景 3
辅助 Checklist 检查,在会话内通过会话变量记录用户的输入项,更新 Checklist 中的内容,并在后续对话中检查遗漏项。
示例:开始对话后,LLM 会要求用户在对话框内输入 Checklist 所涉及的事项,用户一旦提及了 Checklist 中的内容,将会更新并存储至会话变量内。LLM 会在每轮对话后提醒用户继续补充遗漏项。

配置流程:
设置会话变量: 首先设置一个会话变量
ai_checklist,在 LLM 内引用该变量作为上下文进行检查。变量赋值/写入: 每一轮对话时,在 LLM 节点内检查
ai_checklist内的值并比对用户输入,若用户提供了新的信息,则更新 Checklist 并将输出内容通过变量赋值节点写入到ai_checklist内。变量读取: 每一轮对话读取
ai_cheklist内的值并比对用户输入直至所有 checklist 完成。
使用变量赋值节点
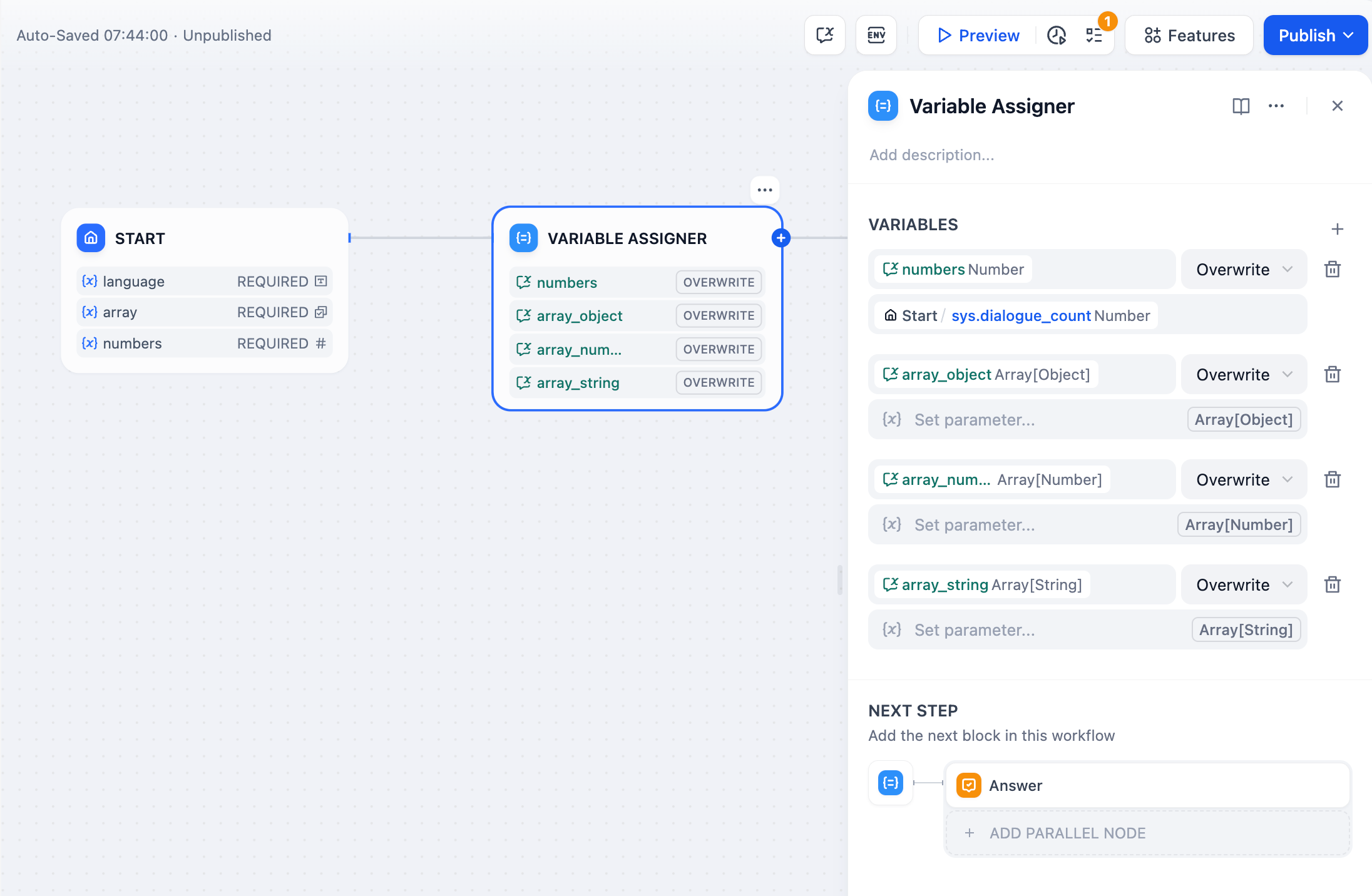
点击节点右侧 + 号,选择 “变量赋值” 节点,配置需要被赋值的变量与源变量。变量赋值节点支持同时为多个变量赋值。
设置变量
变量: 选择需要被赋值的变量。
设置变量: 选择需要赋值的变量,即指定需要被转换的源变量。
上图的变量赋值逻辑:将用户在初始页面填写的语言偏好 Start/language 变量赋值至系统级会话变量 language 内。
指定变量的写入模式
目标变量的数据类型将影响变量的写入模式。以下是不同变量间的写入模式:
目标变量的数据类型为
String。
覆盖,将源变量直接覆盖至目标变量
清空,清空所选中变量中的内容
设置,手动指定一个值,无需设置源变量
目标变量的数据类型为
Number。
覆盖,将源变量直接覆盖至目标变量
清空,清空所选中变量中的内容
设置,手动指定一个值,无需设置源变量
数字处理,对目标变量进行
加减乘除操作
目标变量的数据类型为
Object。
覆盖,将源变量的内容直接覆盖至目标变量
清空,清空所选中变量中的内容
设置,手动指定一个值,无需设置源变量
目标变量的数据类型为
Array。
覆盖,将源变量的内容直接覆盖至目标变量
清空,清空所选中变量中的内容
追加,在目标的数组变量中添加一个新的元素
扩展,在目标的数组变量中添加新的数组,即一次性添加多个元素
Last updated