
3. 设定索引方法与检索设置
选定内容的分段模式后,接下来设定对于结构化内容的索引方法与检索设置。
设定索引方法
正如搜索引擎通过高效的索引算法匹配与用户问题最相关的网页内容,索引方式是否合理将直接影响 LLM 对知识库内容的检索效率以及回答的准确性。
提供“**高质量”**与”经济“ 两种索引方法,其中分别提供不同的检索设置选项:
注意: 原 **Q&A 模式(仅适用于社区版)**已成为高质量索引方法下的一个可选项。
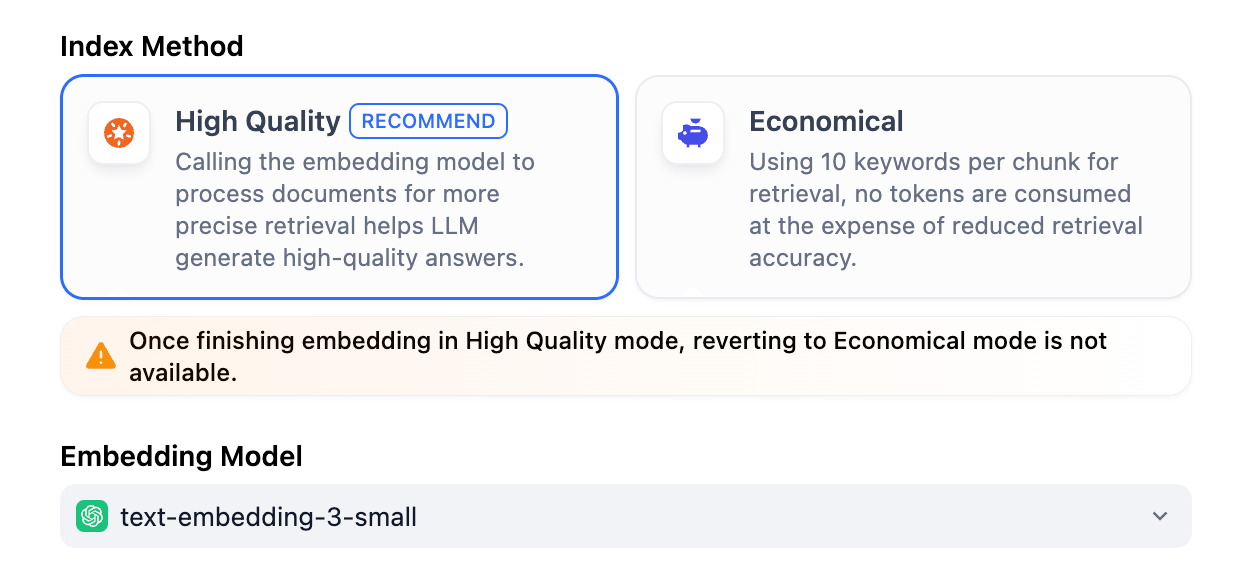
高质量
在高质量模式下,使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息;使得用户问题与文本之间的匹配能够更加精准。
将内容块向量化并录入至数据库后,需要通过有效的检索方式调取与用户问题相匹配的内容块。高质量模式提供向量检索、全文检索和混合检索三种检索设置。关于各个设置的详细说明,请继续阅读检索设置。
选择高质量模式后,当前知识库的索引方式无法在后续降级为 “经济”索引模式。如需切换,建议重新创建知识库并重选索引方式。
如需了解更多关于嵌入技术与向量的说明,请参考《Embedding 技术与 Dify》。
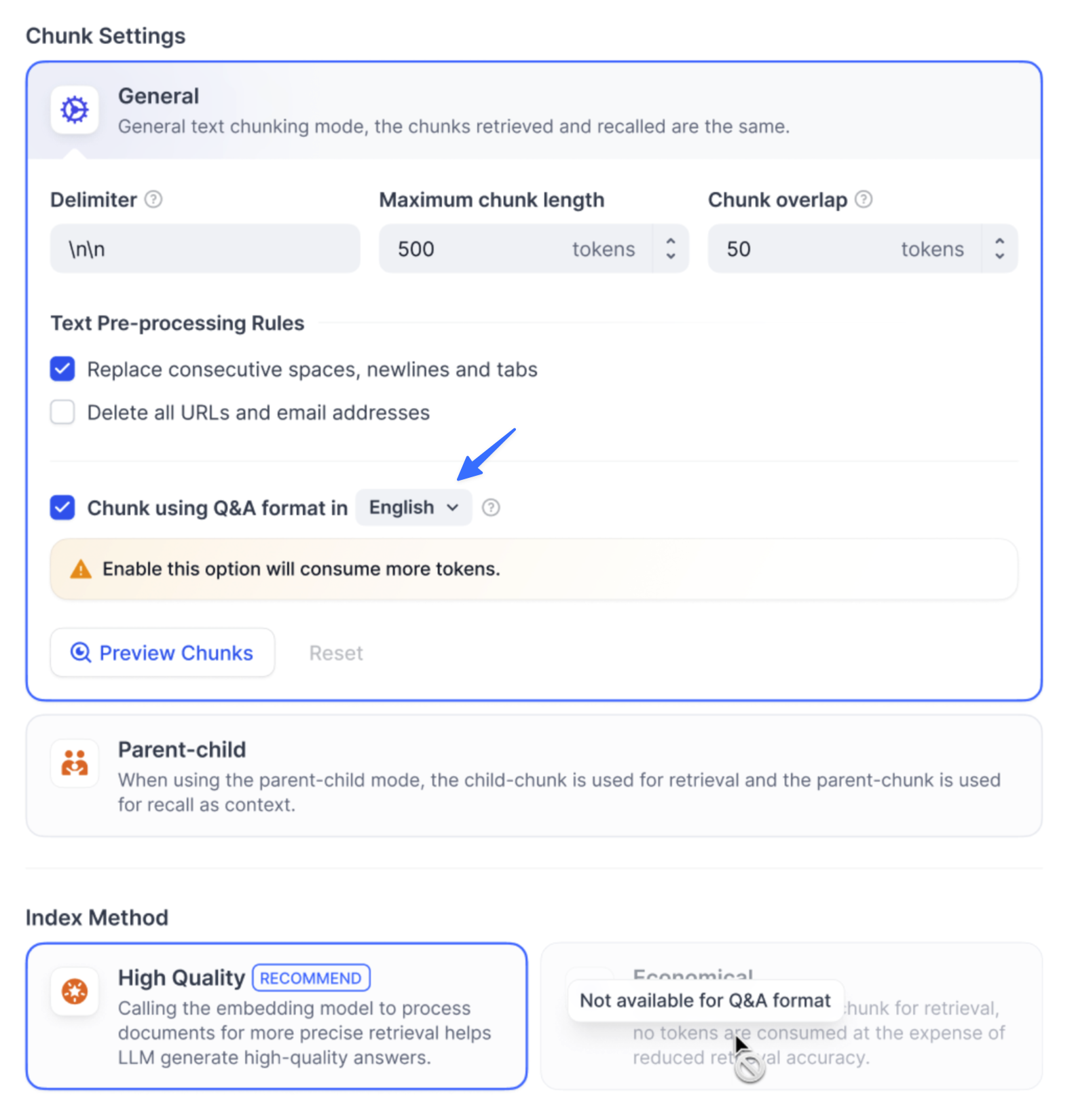
启用 Q&A 模式(可选,仅适用于社区版)
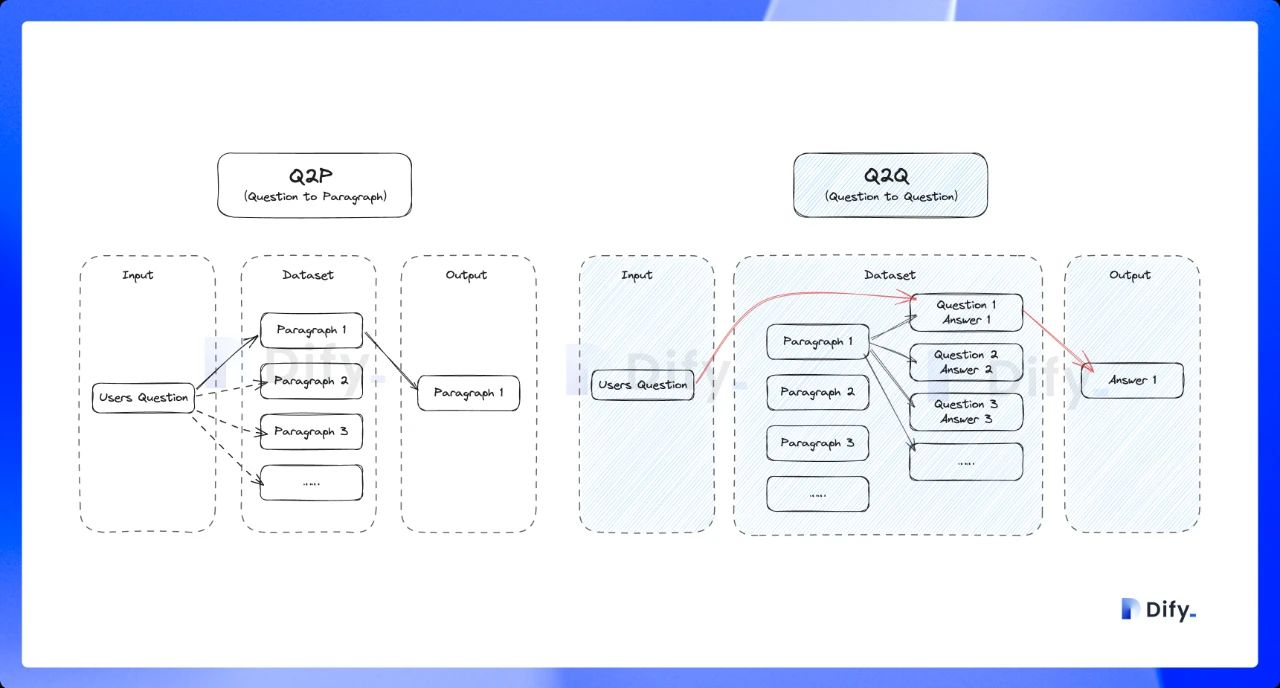
开启该模式后,系统将对已上传的文本进行分段。总结内容后为每个分段自动生成 Q&A 匹配对。与常见的 「Q to P」(用户问题匹配文本段落)策略不同,QA 模式采用 「Q to Q」(问题匹配问题)策略。
这是因为 「常见问题」 文档里的文本通常是具备完整语法结构的自然语言,Q to Q 模式会令问题和答案的匹配更加清晰,并同时满足一些高频和高相似度问题的提问场景。
Q&A 模式仅支持处理 「中英日」 三语。启用该模式后可能会消耗更多的 LLM Tokens,并且无法使用经济型索引方法。
当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案。这种方式更加精确,因为它直接针对用户问题进行匹配,可以更准确地帮助用户检索真正需要的信息。
经济
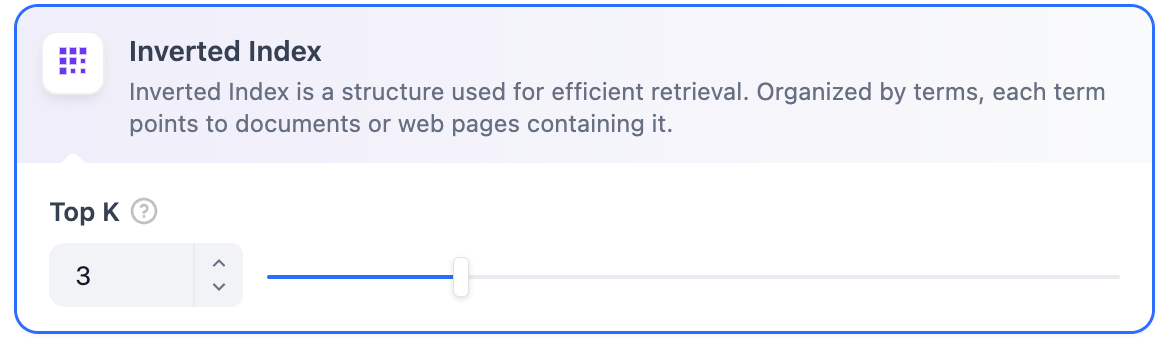
在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。对于检索到的区块,仅提供倒排索引方式选择最相关的区块,详细说明请阅读下文。
选择经济型索引方式后,若感觉实际的效果不佳,可以在知识库设置页中升级为 “高质量”索引方式。

指定检索方式
知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。这将决定 LLM 所能获取的背景信息,从而影响生成结果的准确性和可信度。
常见的检索方式包括基于向量相似度的语义检索,以及基于关键词的精准匹配:前者将文本内容块和问题查询转化为向量,通过计算向量相似度匹配更深层次的语义关联;后者通过倒排索引,即搜索引擎常用的检索方法,匹配问题与关键内容。
不同的索引方法对应差异化的检索设置。
高质量索引
在高质量索引方式下,Dify 提供向量检索、全文检索与混合检索设置:
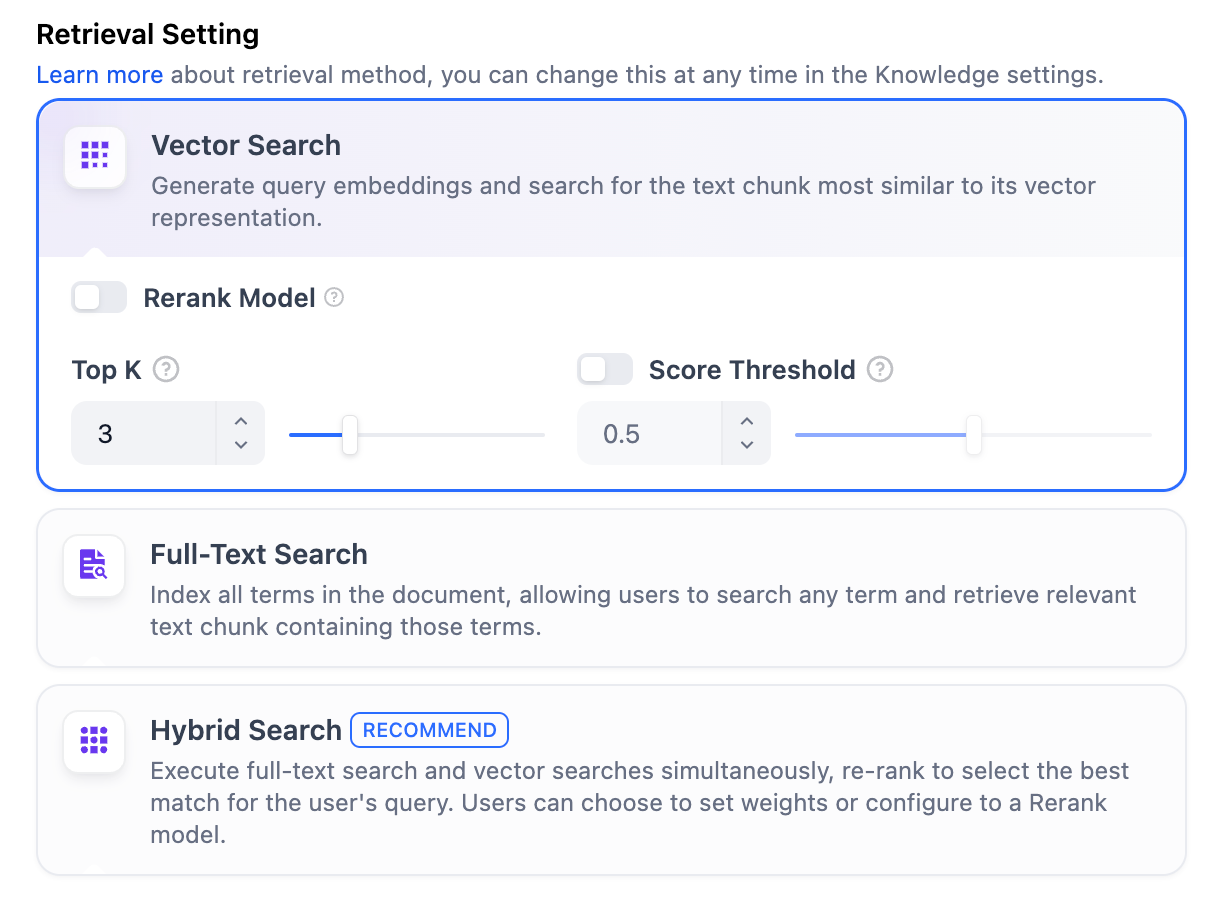
向量检索
定义: 向量化用户输入的问题并生成查询文本的数学向量,比较查询向量与知识库内对应的文本向量间的距离,寻找相邻的分段内容。
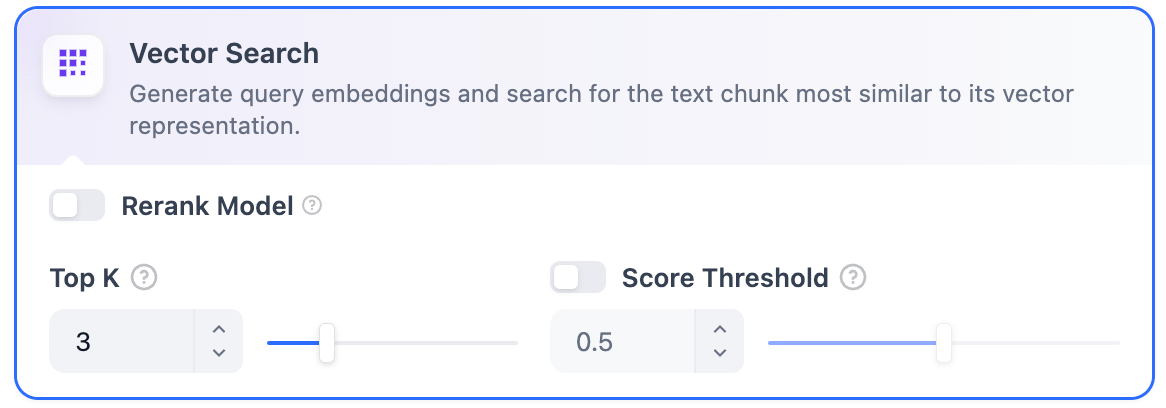
向量检索设置:
Rerank 模型: 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由向量检索召回的内容分段,以优化排序结果。帮助 LLM 获取更加精确的内容,辅助其提升输出的质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
TopK: 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
Score 阈值: 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。
全文检索
定义: 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
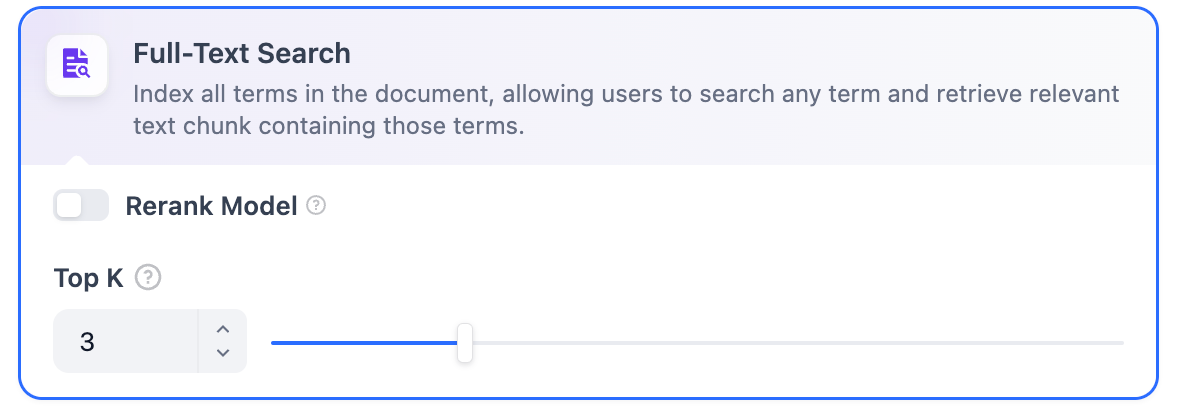
Rerank 模型: 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由全文检索召回的内容分段,以优化排序结果。向 LLM 发送经过重排序的分段,辅助其提升输出的内容质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
TopK: 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
Score 阈值: 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。
混合检索
定义: 同时执行全文检索和向量检索,或 Rerank 模型,从查询结果中选择匹配用户问题的最佳结果。
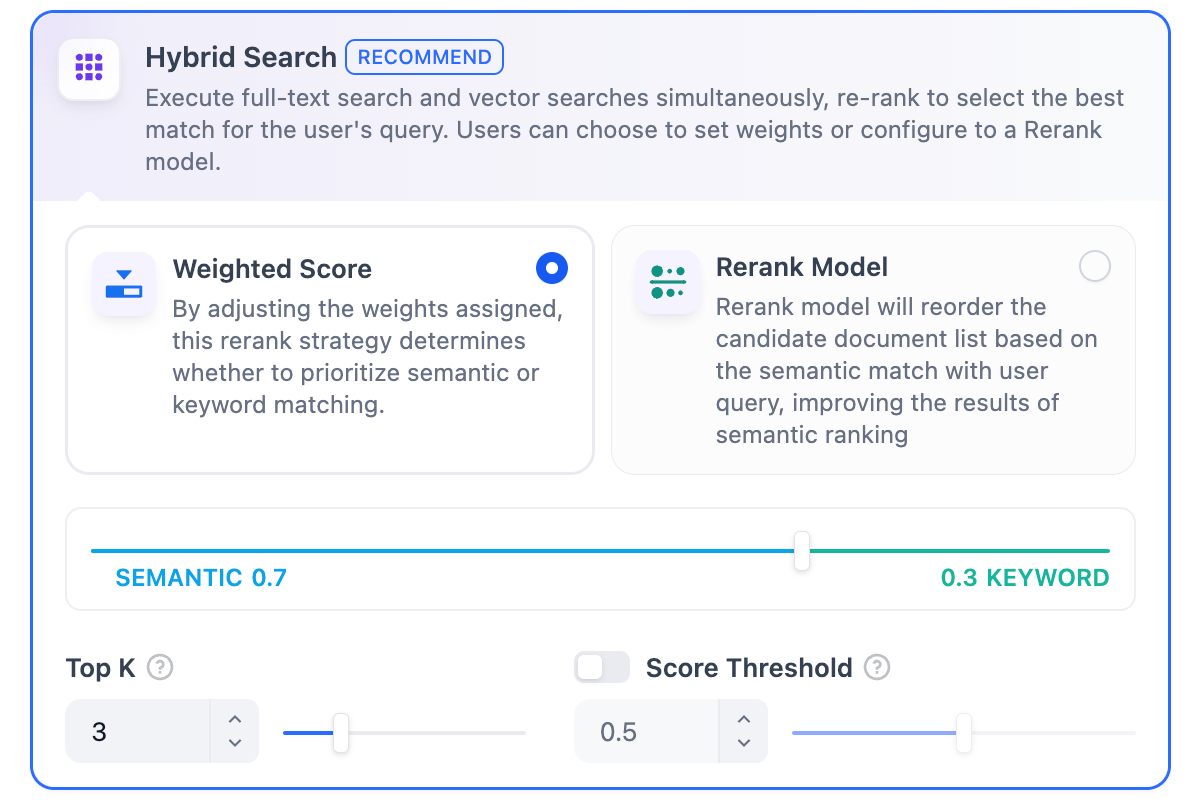
在混合检索设置内可以选择启用 “权重设置” 或 “Rerank 模型”。
权重设置
允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
将语义值拉至 1
仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
将关键词的值拉至 1
仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
自定义关键词和语义权重
除了将不同的数值拉至 1,你还可以不断调试二者的权重,找到符合业务场景的最佳权重比例。
语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:《Dify:Embedding 技术与 Dify 知识库设计/规划》。
Rerank 模型
默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由混合检索召回的内容分段,以优化排序结果。向 LLM 发送经过重排序的分段,辅助其提升输出的内容质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
“权重设置” 和 “Rerank 模型” 设置内支持启用以下选项:
TopK: 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
Score 阈值: 用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5。数值越高,预期被召回的文本数量越少。
阅读更多
指定检索设置后,你可以参考以下文档查看在实际场景下,关键词与内容块的匹配情况。
召回测试/引用归属Last updated