
Integrating with GPUStack for Local Model Deployment
Deploying GPUStack
Linux or MacOS
curl -sfL https://get.gpustack.ai | sh -s -Windows
Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).ContentDeploying LLM
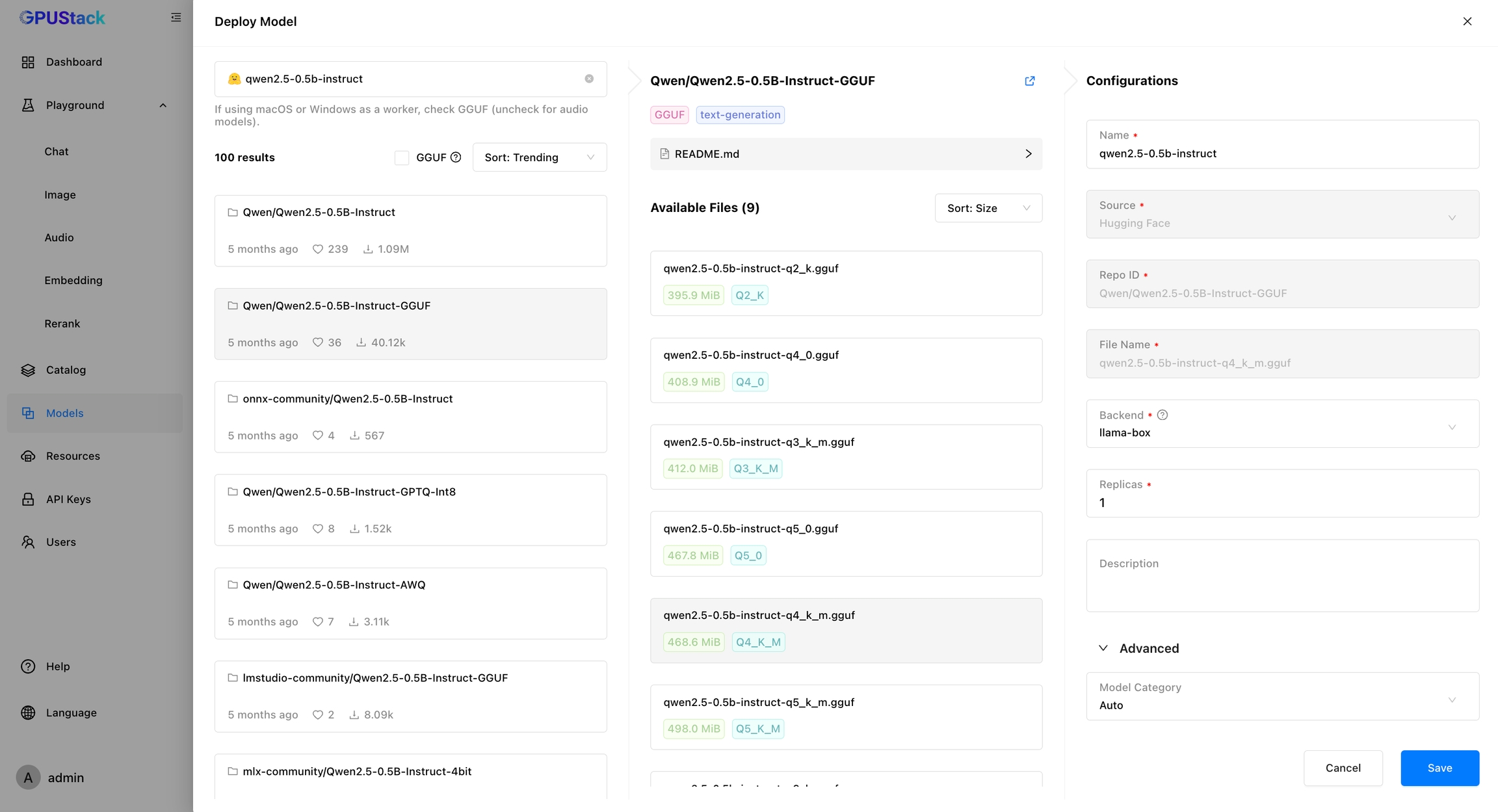
Create an API Key
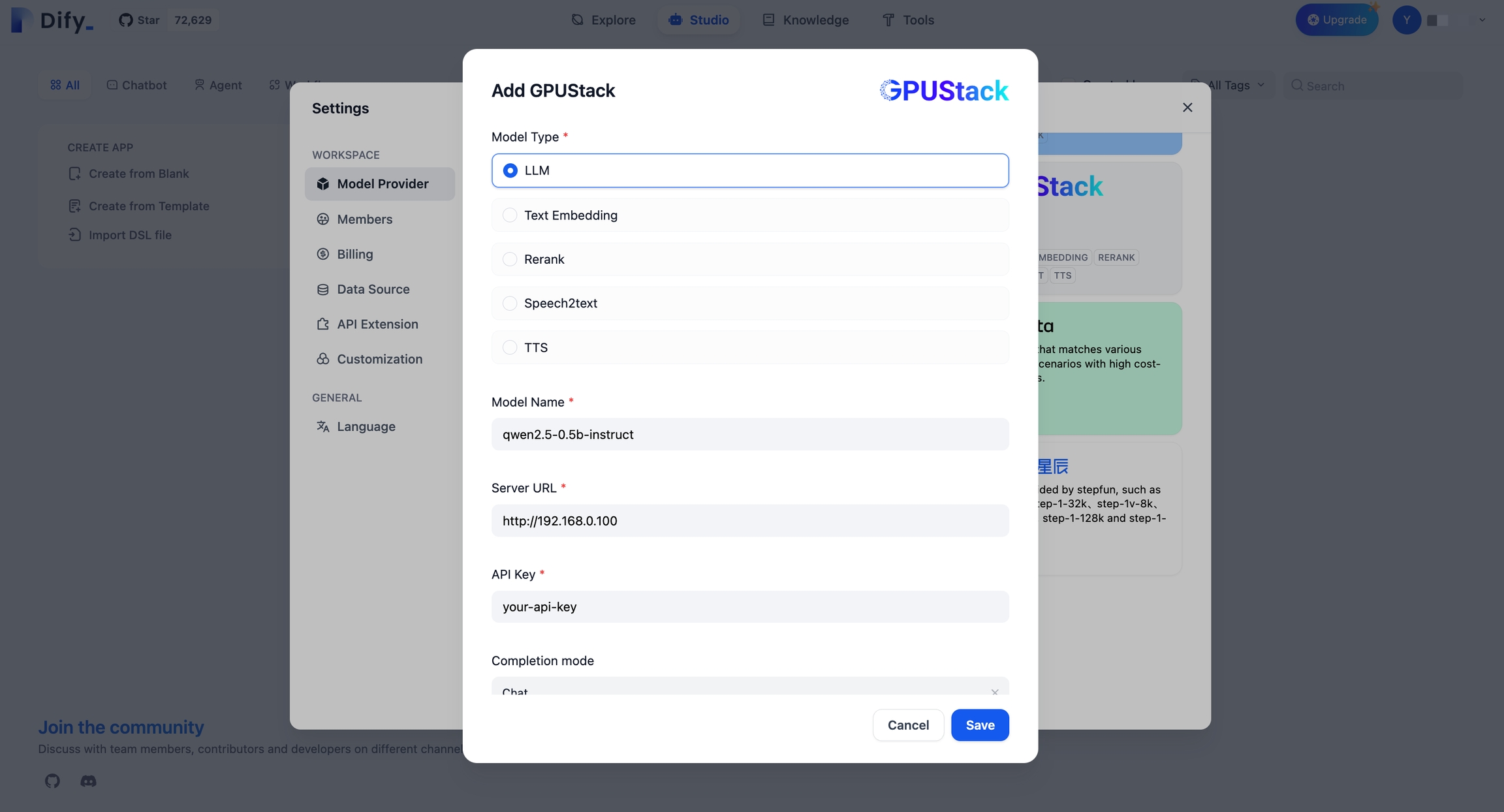
Integrating GPUStack into Dify
Last updated